레디스란?
Redis는 REmote DIctionary Server의 약자로 고성능 원자적(Atomic) 연산을 지원하는 인메모리(In-Memory) 데이터 구조 저장소입니다.
레디스(Redis) 기술적 특징
인메모리

전통적인 RDBMS에서는 데이터 영속화를 최우선으로 생각해 데이터를 보조기억장치(HDD/SSD)에 저장을 합니다. 반면에 레디스는 데이터를 주메모리에 상주시켜 나노초 단위의 메모리 접근 속도를 보장합니다.
레디스는 별로 비즈니스 로직이 없습니다. 따라서 빠른 메모리 접근 속도로 인해 보다 적은 자원으로 더 많은 처리량을 수행할 수 있습니다.
풍부한 자료구조


Strings, Lists, Sets, Hashes, Sorted Sets(ZSet) 등을 기본 지원하며, 최근에는 Streams, Bitmaps, HyperLogLog 등 확률적 자료구조와 스트리밍 모델까지 확장 지원하고 있습니다.
자료구조를 지원한다는 것은 개발자가 직접 데이터를 가공할 필요가 없어 구현의 복잡도가 낮아집니다.
싱글 스레드(이벤트 루프 모델)


멀티 스레드에서 발생하는 컨텍스트 스위칭과 데이터 접근 락을 제거해 효율을 극대화합니다.
다만, 레디스 6.0부터는 네트워크 I/O에 한해 멀티 스레딩이 도입되었습니다.
웹에서 주요 사용방식
주로 MSA 환경에서 레디스는 서비스 간의 상태 공유와 비동기 통신을 담당합니다. 특히 분산 락 기능을 사용하여 여러 서버가 동일한 로직의 접근을 효과적으로 제어할 수 있습니다.
또한 Sorted Sets 을 사용하여 실시간 랭킹 같은 고비용 작업을 손쉽게 처리합니다.
주의점
주 메모리는 유한하다

보조 기억장치에 비해 주 메모리는 스케일업이 훨씬 제한적입니다.
반드시 메모리에서 지워지는 전략을 생각해야 합니다. 데이터에 유효시간, 오래된 데이터 방출 등
또한 결국 메모리를 캐시처럼 쓰기 때문에 빈번한 할당/해제를 유발하고 이는 메모리 파편화를 유발합니다.
싱글 스레드
데이터셋 전체를 다루는 명령어는 주의가 필요합니다. 그 처리를 위해 모든 작업이 블록킹됩니다. 애초에 싱글 스레드 이벤트 루프 방식은 무거운 작업을 수행하기 적합하지 않습니다.
또한 결국 싱글 스레드이기 때문에 수직 확장이 사실상 불가능합니다. 성능을 위해선 Redis Cluster를 통한 수평 확장은 선택이 아닙니다.
영속성 트레이드 오프

기본적으로 캐시지만 데이터를 복구하는 방법을 제공합니다. 다만, 복구가 완벽할 수록 성능은 타협해야 합니다.
RDB (Redis Database): 특정 시점의 메모리 데이터를 스냅샷 형태로 디스크에 저장하는 방식. 백업 용도로 주로 사용됨. 스냅샷 사이 데이터 유실 가능
AOF (Append Only File): 모든 쓰기 명령을 순차적으로 로그 파일에 기록하여 데이터를 복구하는 방식. RDB보다 데이터 유실 가능성이 적음. 쓰기 속도 저하
자체 Q&A
왜 레디스여야 하나?
먼저 HTTP는 무상태 프로토콜입니다. 만약 상태관리가 필요하다면 저장소가 필요로 합니다. 그렇지만 레디스여야 하는 이유는 있을까요? DB도 동일한 역할을 분명히 수행할 수 있습니다. 그렇다면 왜 레디스를 써야 할까요? 제가 생각하는 레디스 사용하는 이유는 일반적인 RDB보다 빨라서입니다. 그렇다면 빠르다는 것은 무슨 의미를 내포하고 있을까요?
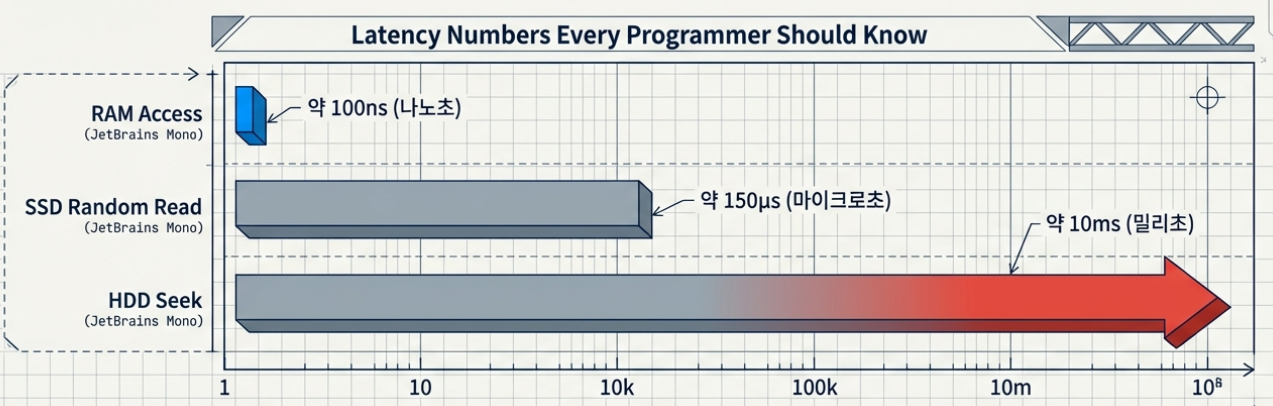
생각해보면 인간에게 10ns나 10ms는 체감 차이를 느낄 수 없습니다. 그렇다면 빠른 게 왜 장점일까요?
웹 서비스는 1명을 위한 서비스가 아닙니다. 따라서 빨리 처리하면 할수록 본연의 핵심 기능인 캐시 역할을 더 훌륭히 수행하는 것입니다.
모든 상황은 고정 상수로 두고 단지 레디스인지 RDB인지만 비교를 한다면 같은 자원으로 레디스는 동일한 시간에 최소 10 배에서 100 배까지 차이가 납니다.
왜 이렇게 까지 속도차이가 나는지는 위에 말한 물리적 특징을 포함해서 아래와 같은 기능적 특징이 더해져서 나타나는 현상입니다.
/* 이해를 위한 단순 참고용 */
[RDB의 데이터 처리 경로]
네트워크 수신
커넥션 스레드 할당 (Context Switch 발생)
SQL 파싱 & 문법 검사 (CPU 소모)
쿼리 최적화 (실행 계획 수립)
테이블/행 잠금 (Lock Check)
B-Tree 인덱스 탐색
데이터 페이지 읽기 (Buffer Pool 없으면 Disk I/O)
트랜잭션 로그 기록 (WAL - Disk I/O)
결과 반환
[Redis의 데이터 처리 경로]
네트워크 수신 (Multiplexing)
명령 해석 (단순 문자열 매칭)
메모리 주소 직접 접근 (Hash lookup - O(1))
결과 반환핵심은 DB는 데이터 중심으로 보다 많은 부수작업들이 들어가서 느리고, 레디스는 데이터를 빠르게 조회하기 위해 그런 부수작업이 적다는 것입니다.
주메모리가 주는 이점은 무엇인가?
단순히 빠르다는 것은 누구나 알지만 어떤 점에서 빠른 지 알아보겠습니다.
RDB에서 디스크의 접근은 매우 느립니다. 그렇기 때문에 B+Tree같은 자료구조로 최소한의 접근을 지향합니다. 반면에 레디스는 주메모리를 사용하므로 말그대로 Random Access Memory 뜻대로 Random I/O가 굉장히 빠릅니다. 이런 차이로 레디스는 LinkedList 기반 자료구조를 사용하기 적합하고 이를 잘 활용한 데이터 구조가 Sorted Sets 입니다.

'개발' 카테고리의 다른 글
| 요즘 개발자를 위한 시스템 설계 수업 - 3장 분산 시스템의 이론과 데이터 구조 1 (1) | 2026.02.27 |
|---|---|
| 요즘 개발자를 위한 시스템 설계 수업 - 2장 분산 시스템의 속성 (1) | 2026.02.23 |
| 요즘 개발자를 위한 시스템 설계 수업 - 1장 시스템 설계의 기본 (0) | 2026.02.20 |
| 레디스 - 쓰기 전략 (0) | 2026.02.15 |
| 레디스 - 읽기 전략 (0) | 2026.02.08 |