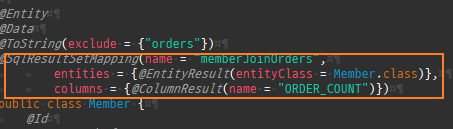
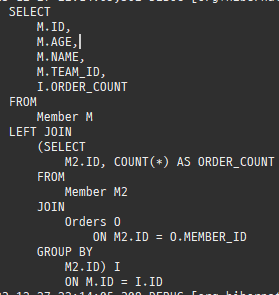
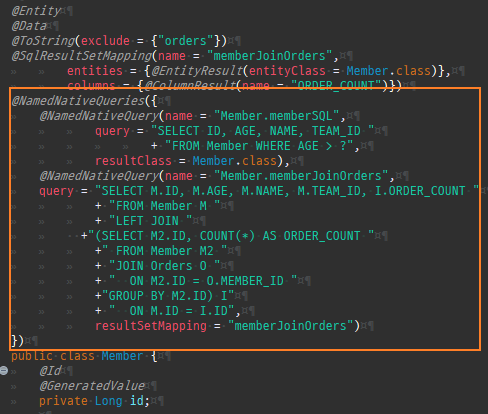
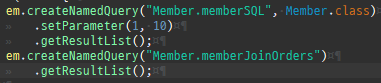
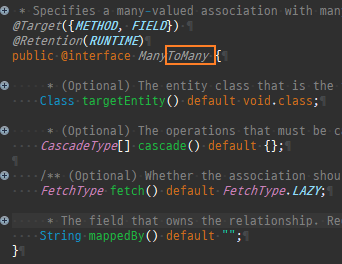
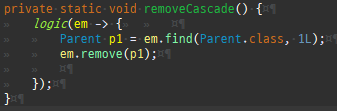
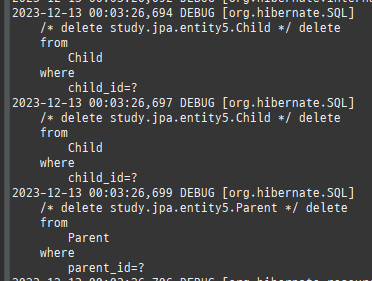
@Entity @Data @ToString(exclude = {"orders"}) public class Member { @Id @GeneratedValue private Long id; @Column(name = "name") private String username; private int age; @OneToMany(mappedBy = "member", cascade = CascadeType.ALL, orphanRemoval = true) private List<Order> orders = new ArrayList<>(); @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "team_id") private Team team; public void setTeam(Team team) { if (this.team != null) { this.team.getMembers().remove(this); } this.team = team; team.getMembers().add(this); } public void addOrder(Order order) { orders.add(order); order.setMember(this); } }
@Entity @Data public class Team { @Id @GeneratedValue private Long id; private String name; @OneToMany(mappedBy = "team", cascade = CascadeType.ALL, orphanRemoval = true) private List<Member> members = new ArrayList<>(); public void addMember(Member member) { members.add(member); member.setTeam(this); } }
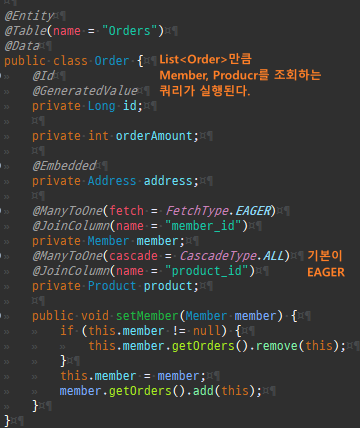
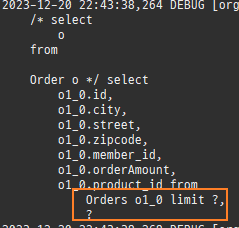
@Entity @Table(name = "Orders") @Data public class Order { @Id @GeneratedValue private Long id; private int orderAmount; @Embedded private Address address; @ManyToOne @JoinColumn(name = "member_id") private Member member; @ManyToOne(cascade = CascadeType.ALL) @JoinColumn(name = "product_id") private Product product; public void setMember(Member member) { if (this.member != null) { this.member.getOrders().remove(this); } this.member = member; member.getOrders().add(this); } }
@Entity @Data public class Product { @Id @GeneratedValue private Long id; private String name; private int price; private int stockAmount; }
@Embeddable @Data @NoArgsConstructor @AllArgsConstructor public class Address { private String city; private String street; private String zipcode; }
public class Main { static EntityManagerFactory emf = Persistence.createEntityManagerFactory("studyjpa"); public static void main(String[] args) { save(); emf.close(); }
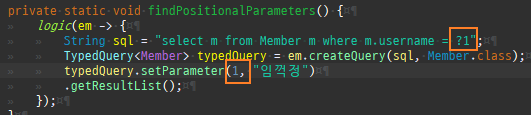
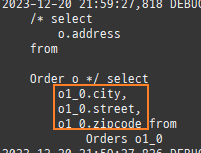
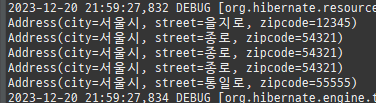
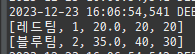
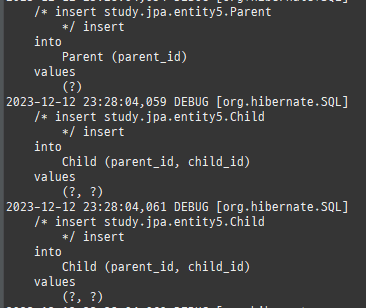
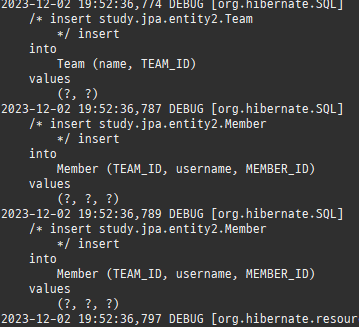
private static void save() { logic(em -> { Member m1 = new Member(); m1.setAge(20); m1.setUsername("홍길동"); Member m2 = new Member(); m2.setAge(30); m2.setUsername("임꺽정"); Member m3 = new Member(); m3.setAge(40); m3.setUsername("유관순"); Team t1 = new Team(); t1.setName("레드팀"); t1.addMember(m1); t1.addMember(m2); em.persist(t1); Team t2 = new Team(); t2.setName("블루팀"); t2.addMember(m2); t2.addMember(m3); em.persist(t2); Product p1 = new Product(); p1.setName("삼겹살"); p1.setPrice(10000); p1.setStockAmount(10); em.persist(p1); Product p2 = new Product(); p2.setName("오징어"); p2.setPrice(15000); p2.setStockAmount(20); em.persist(p2); Product p3 = new Product(); p3.setName("돈까스"); p3.setPrice(12000); p3.setStockAmount(30); em.persist(p3); Order o1 = new Order(); o1.setAddress(new Address("서울시", "을지로", "12345")); o1.setMember(m1); o1.setOrderAmount(1); o1.setProduct(p1); em.persist(o1); Order o2 = new Order(); o2.setAddress(new Address("서울시", "종로", "54321")); o2.setMember(m1); o2.setOrderAmount(1); o2.setProduct(p2); em.persist(o2); Order o3 = new Order(); o3.setAddress(new Address("서울시", "종로", "54321")); o3.setMember(m2); o3.setOrderAmount(1); o3.setProduct(p2); em.persist(o3); Order o4 = new Order(); o4.setAddress(new Address("서울시", "종로", "54321")); o4.setMember(m3); o4.setOrderAmount(1); o4.setProduct(p2); em.persist(o4); Order o5 = new Order(); o5.setAddress(new Address("서울시", "통일로", "55555")); o5.setMember(m3); o5.setOrderAmount(1); o5.setProduct(p3); em.persist(o5); }); }
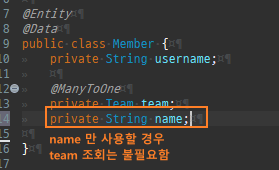
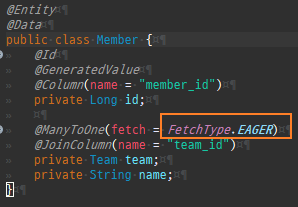
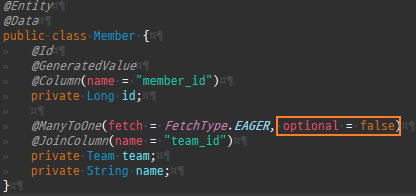
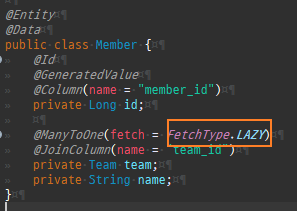
@Entity @Data public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; @ManyToOne private Team team; private String name; }
@Entity @Data public class Team { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String name; }
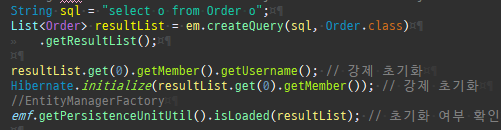
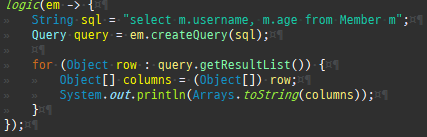
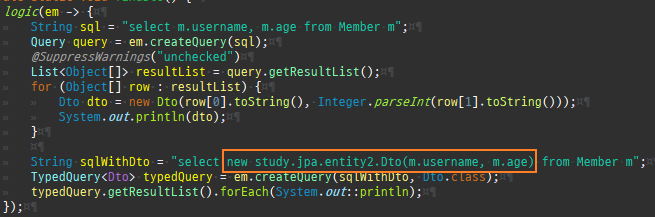
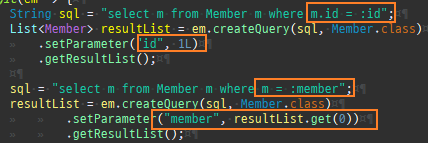
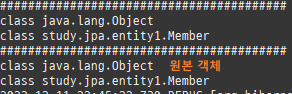
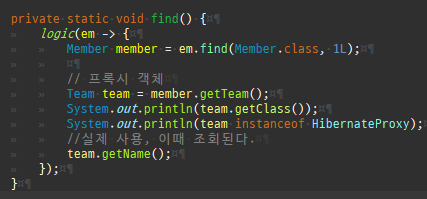
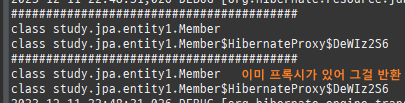
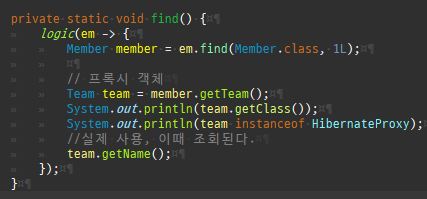
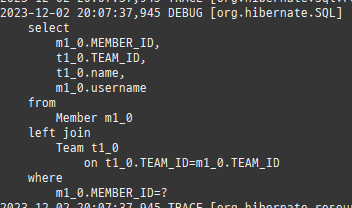
private static void find() { logic(em -> { Member member = em.find(Member.class, 1L); System.out.println("#########################################"); System.out.println(member.getClass().getSuperclass()); System.out.println(member.getClass()); // Member 프록시를 반환 Member reference = em.getReference(Member.class, 1L); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(reference.getClass().getSuperclass()); System.out.println(reference.getClass()); }); }
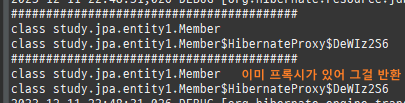
private static void find2() { logic(em -> { // 아무것도 수행 안함 Member reference = em.getReference(Member.class, 1L); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(reference.getClass().getSuperclass()); System.out.println(reference.getClass()); Member member = em.find(Member.class, 1L); System.out.println("#########################################"); System.out.println(member.getClass().getSuperclass()); System.out.println(member.getClass()); }); }
private static void find3() { logic(em -> { Member reference = em.getReference(Member.class, 1L); //준영속 em.detach(reference); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(reference.getClass().getSuperclass()); System.out.println(reference.getClass()); }); }
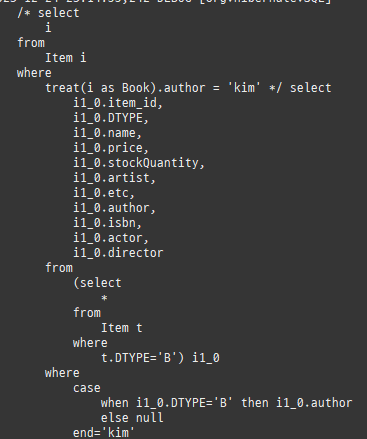
프록시와식별자
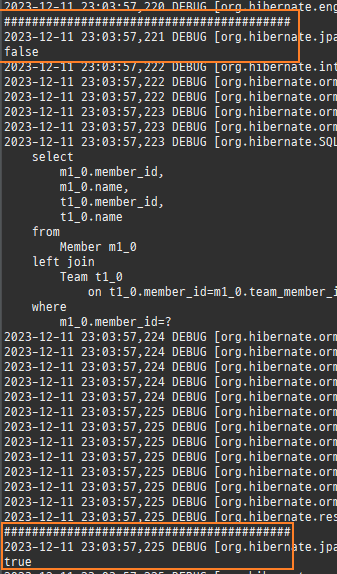
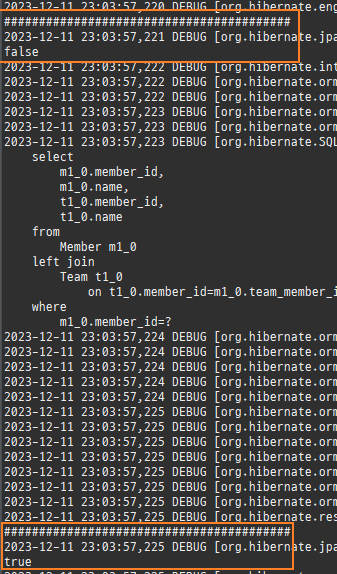
private static void find4() { logic(em -> { Member reference = em.getReference(Member.class, 1L); System.out.println("#########################################"); System.out.println(emf.getPersistenceUnitUtil().isLoaded(reference)); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(emf.getPersistenceUnitUtil().isLoaded(reference)); }); }
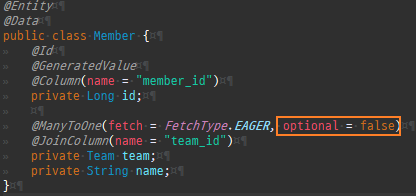
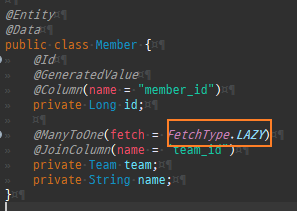
즉시로딩과지연로딩
즉시로딩 연관된엔티티도함께조회
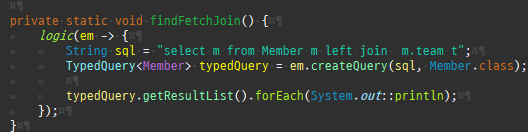
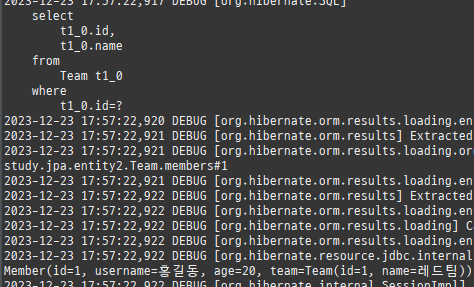
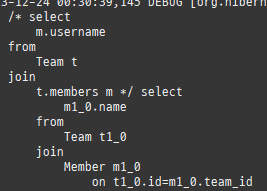
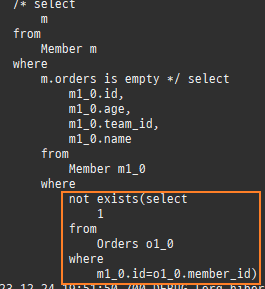
지연로딩 연된된엔티티사용할때조회
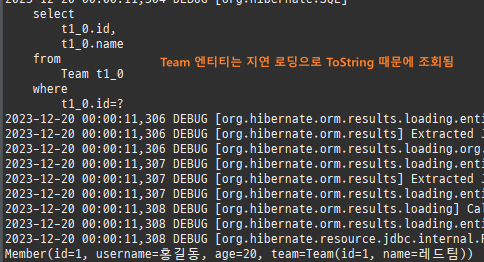
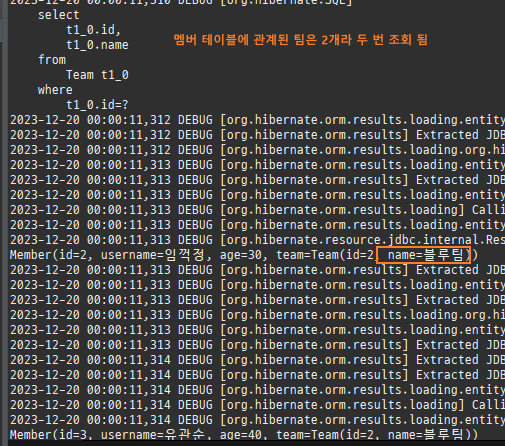
프록시는연관된엔티티를지연로딩할때쓰인다.
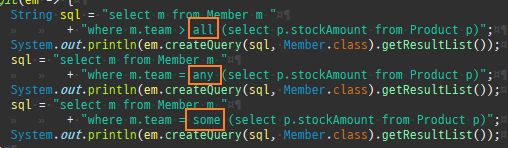
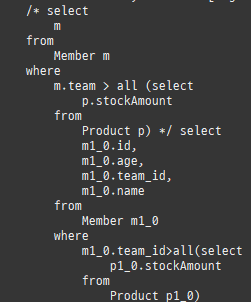
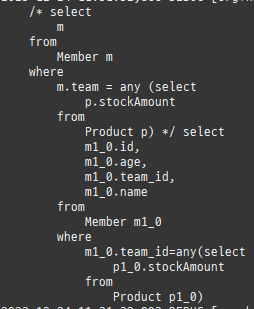
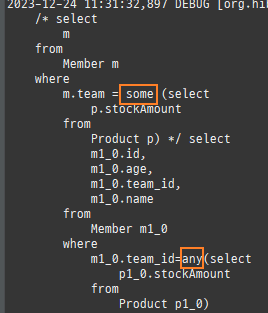
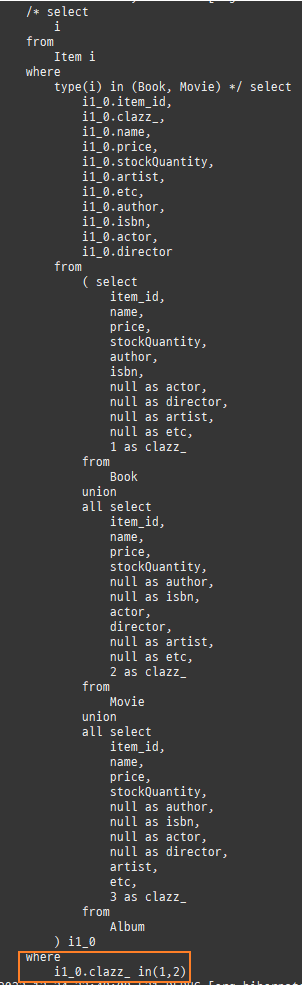
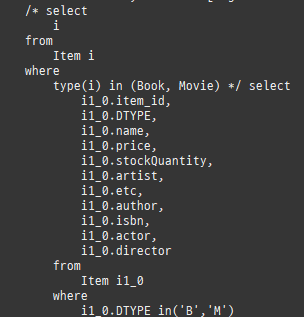
즉시로딩
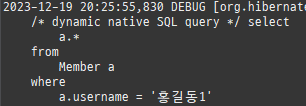
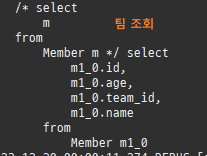
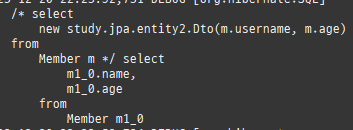
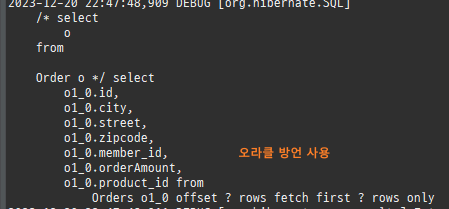
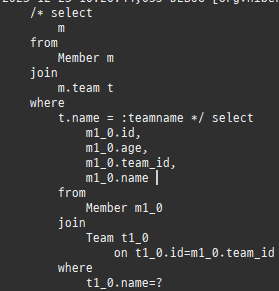
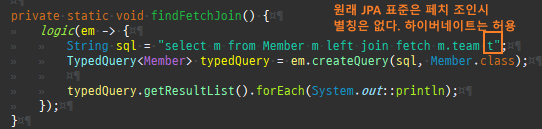
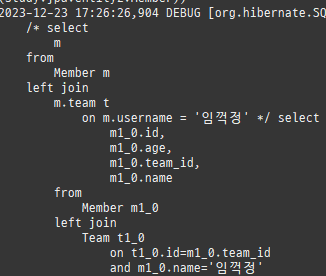
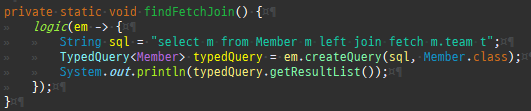
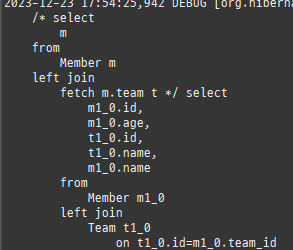
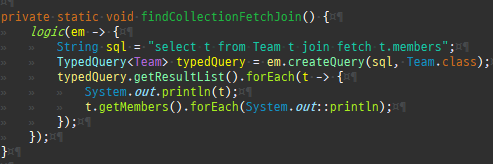
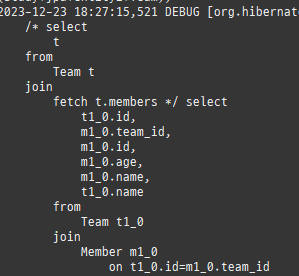
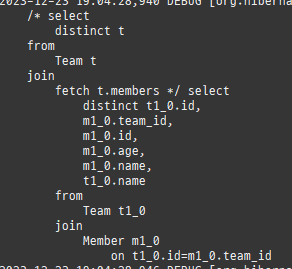
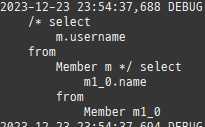
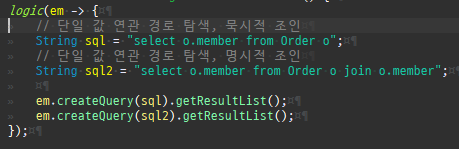
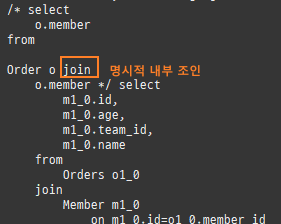
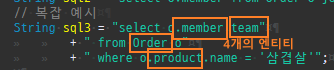
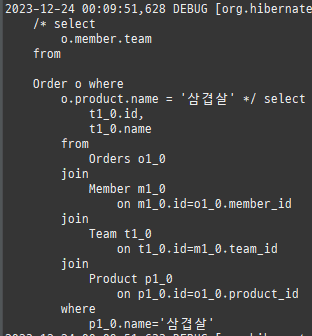
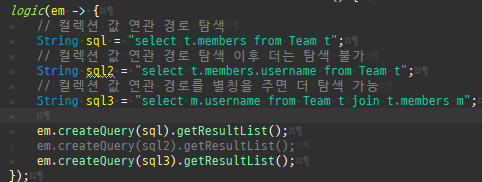
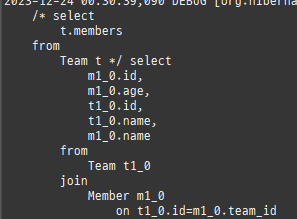
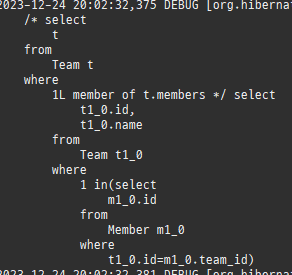
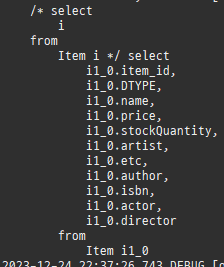
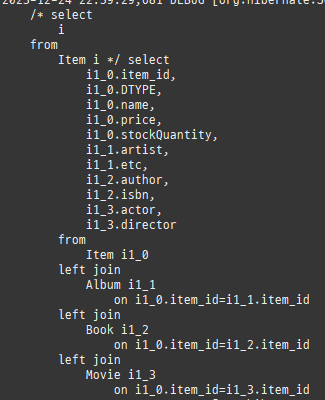
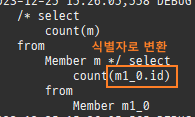
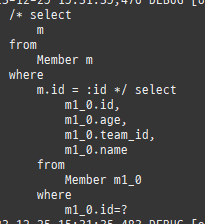
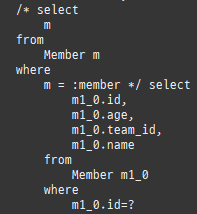
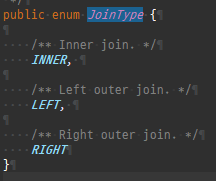
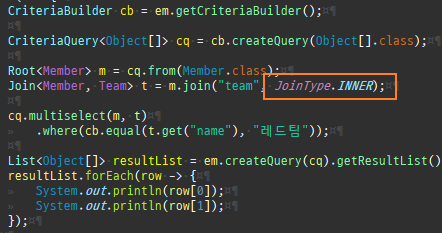
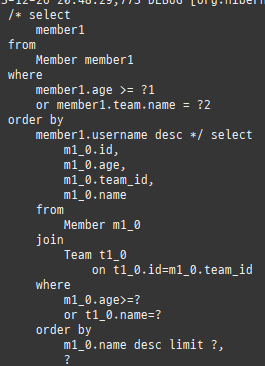
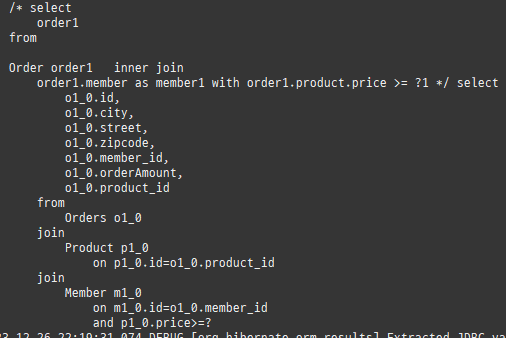
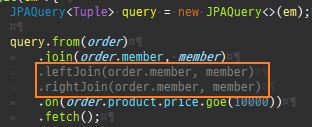
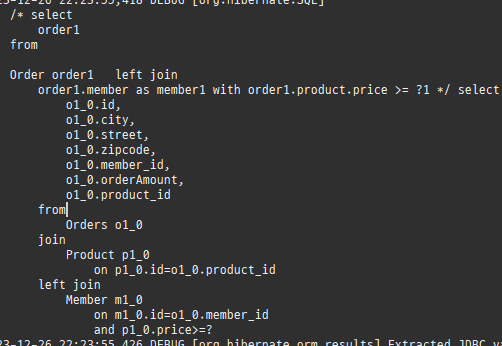
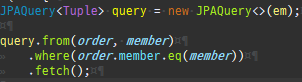
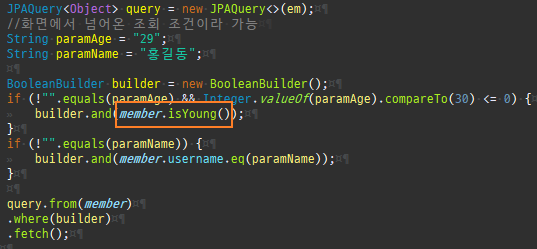
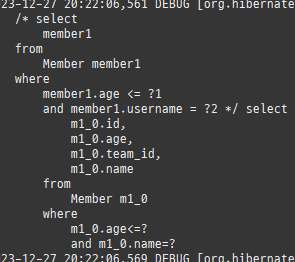
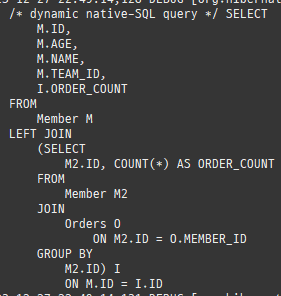
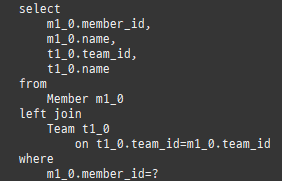
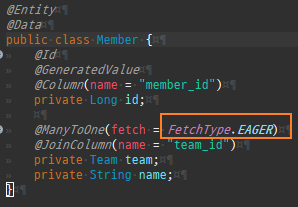
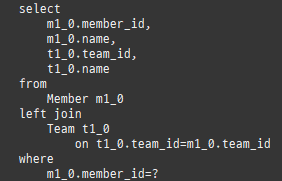
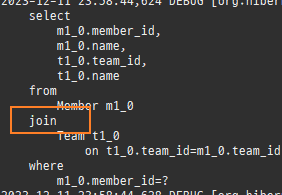
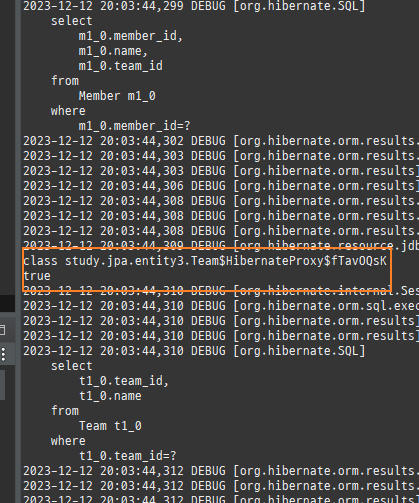
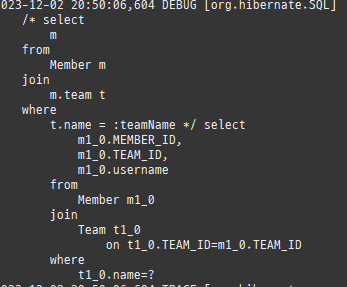
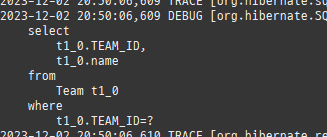
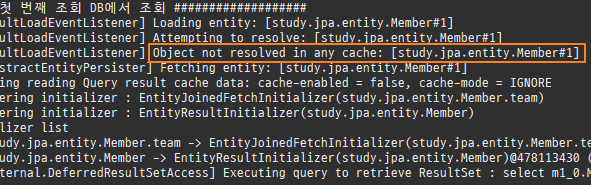
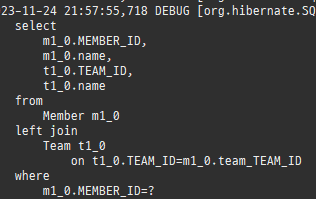
즉시로딩은연관된엔티티를함께보기위해조인쿼리를사용한다.
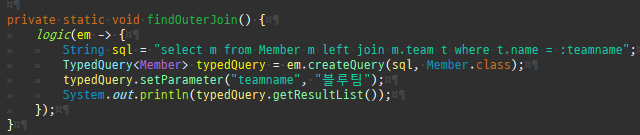
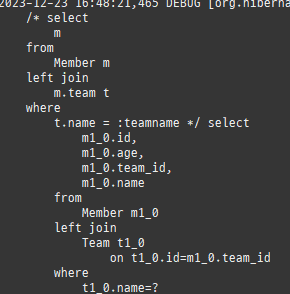
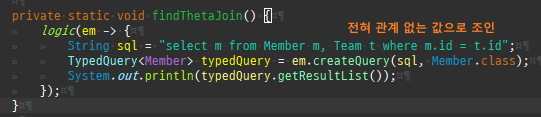
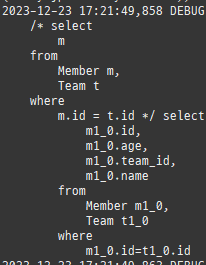
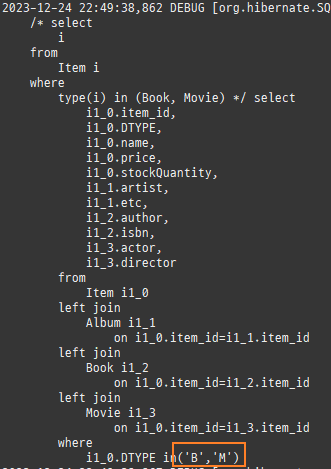
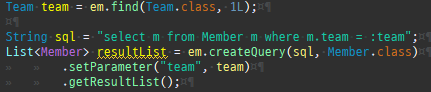
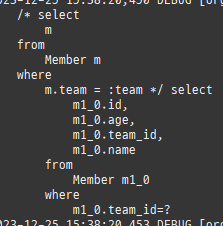
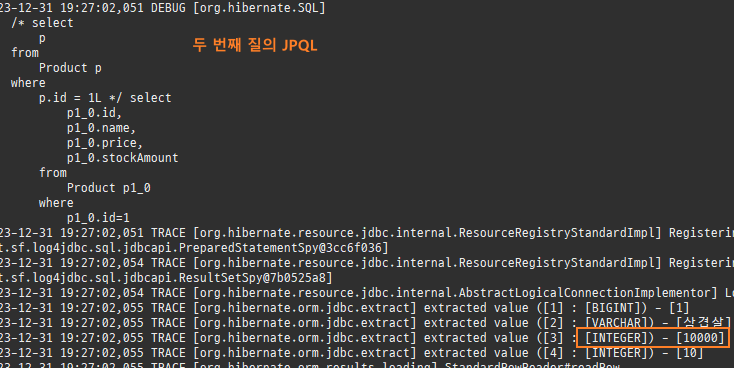
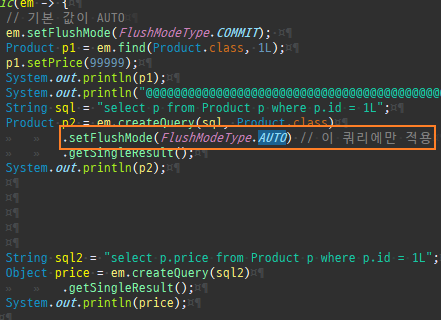
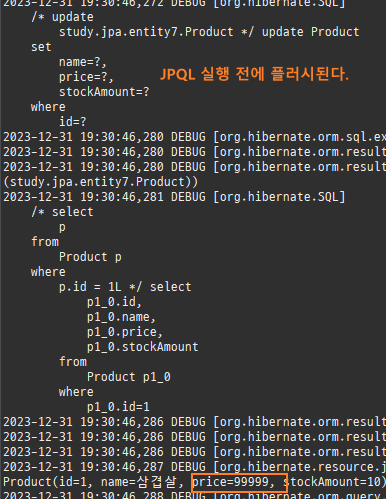
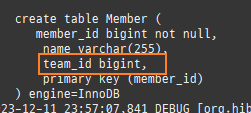
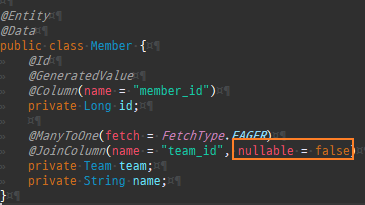
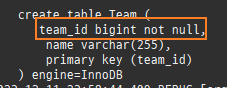
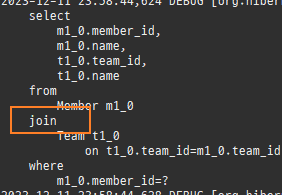
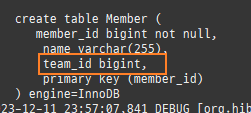
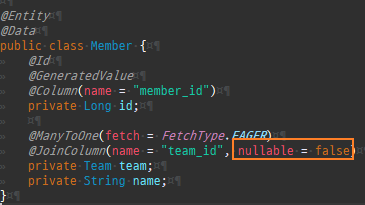
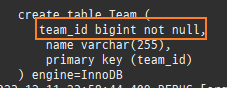
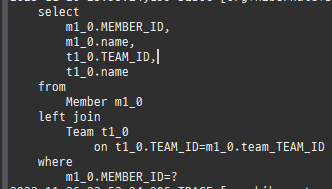
null 제약조건과 JPA 조인전략
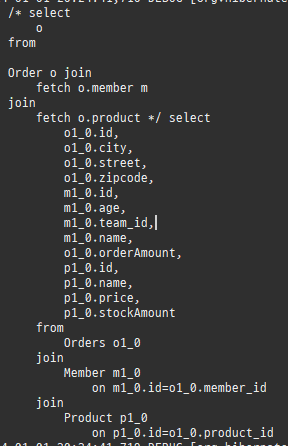
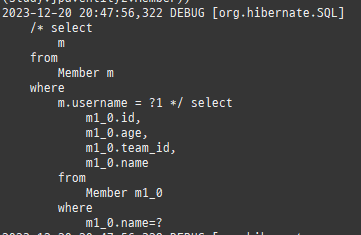
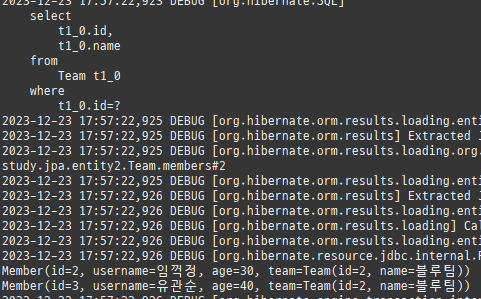
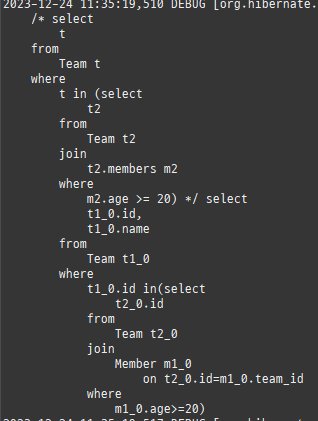
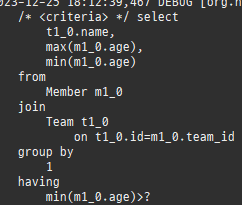
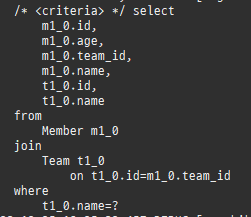
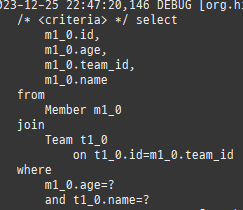
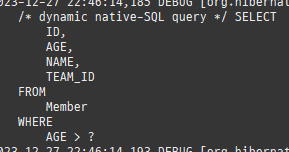
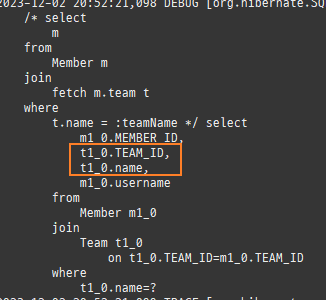
위 sql을보면외부조인이다. 이유는 Member 테이블에 team_id 는 null을허용하기때문이다.
public class Main { static EntityManagerFactory emf = Persistence.createEntityManagerFactory("studyjpa"); public static void main(String[] args) { logic(save()); logic(remove()); emf.close(); }
@Entity @Data public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; @ManyToOne private Team team; private String name; }
@Entity @Data public class Team { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String name; }
private static void find() { logic(em -> { Member member = em.find(Member.class, 1L); System.out.println("#########################################"); System.out.println(member.getClass().getSuperclass()); System.out.println(member.getClass()); // Member 프록시를 반환 Member reference = em.getReference(Member.class, 1L); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(reference.getClass().getSuperclass()); System.out.println(reference.getClass()); }); }
private static void find2() { logic(em -> { // 아무것도 수행 안함 Member reference = em.getReference(Member.class, 1L); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(reference.getClass().getSuperclass()); System.out.println(reference.getClass()); Member member = em.find(Member.class, 1L); System.out.println("#########################################"); System.out.println(member.getClass().getSuperclass()); System.out.println(member.getClass()); }); }
private static void find3() { logic(em -> { Member reference = em.getReference(Member.class, 1L); //준영속 em.detach(reference); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(reference.getClass().getSuperclass()); System.out.println(reference.getClass()); }); }
프록시와식별자
private static void find4() { logic(em -> { Member reference = em.getReference(Member.class, 1L); System.out.println("#########################################"); System.out.println(emf.getPersistenceUnitUtil().isLoaded(reference)); // 첫 사용 한 번만 초기화 수행 reference.getTeam(); System.out.println("#########################################"); System.out.println(emf.getPersistenceUnitUtil().isLoaded(reference)); }); }
즉시로딩과지연로딩
즉시로딩 연관된엔티티도함께조회
지연로딩 연된된엔티티사용할때조회
프록시는연관된엔티티를지연로딩할때쓰인다.
즉시로딩
즉시로딩은연관된엔티티를함께보기위해조인쿼리를사용한다.
null 제약조건과 JPA 조인전략
위 sql을보면외부조인이다. 이유는 Member 테이블에 team_id 는 null을허용하기때문이다.
public class Main { static EntityManagerFactory emf = Persistence.createEntityManagerFactory("studyjpa"); public static void main(String[] args) { logic(save()); logic(remove()); emf.close(); }
@Entity @Data public class A { @Id @Column(name = "a_id") private String id; private String name;; }
@Entity @IdClass(B.BId.class) @Data public class B { @Id @ManyToOne @JoinColumn(name = "a_id") // 외래 키 식별 private A a; @Id @Column(name = "b_id") private String id; private String name;; @NoArgsConstructor @EqualsAndHashCode @Data public static class BId implements Serializable { private String a;//public A a; private String id; //private String id; } }
@Entity @IdClass(C.CId.class) @Data public class C { @Id @ManyToOne @JoinColumns({ @JoinColumn(name = "a_id"), @JoinColumn(name = "b_id") }) private B b; @Id @Column(name = "c_id") private String id; private String name; @NoArgsConstructor @EqualsAndHashCode @Data public static class CId implements Serializable{ private B.BId b;//private B b; private String id; // private String id; } }
public static void main(String[] args) { save(); find(); emf.close(); }
private static void find() { logic(em -> { A a = em.find(A.class, "A_ID"); BId bId = new B.BId(); bId.setA("A_ID"); bId.setId("B_ID"); B b = em.find(B.class, bId); CId cId = new C.CId(); cId.setB(bId); cId.setId("C_ID"); C c = em.find(C.class, cId); }); }
private static void save() { logic(em -> { A a = new A(); a.setId("A_ID"); a.setName("A"); em.persist(a); B b = new B(); b.setA(a); b.setId("B_ID"); b.setName("B"); em.persist(b); C c = new C(); c.setB(b); c.setId("C_ID"); c.setName("C"); em.persist(c); }); }
@EmbeddedId 식별관계
@MapsId 사용이필요
@Entity @Data public class A { @Id @Column(name = "a_id") private String id; private String name;; }
@Entity @Data public class B { @MapsId("AId") //private String AId; @ManyToOne @JoinColumn(name = "a_id") private A a; @EmbeddedId private B.BId id; private String name;; @NoArgsConstructor @EqualsAndHashCode @Data @Embeddable public static class BId implements Serializable { private String AId; //@MapsId("AId") @Column(name = "b_id") private String id; } }
@Entity @Data public class C { @MapsId("BId") //private B.BId BId; @ManyToOne @JoinColumns({ @JoinColumn(name = "a_id"), @JoinColumn(name = "b_id") }) private B b; @EmbeddedId private C.CId id; private String name; @NoArgsConstructor @EqualsAndHashCode @Data @Embeddable public static class CId implements Serializable{ private B.BId BId; //@MapsId("BId") @Column(name = "c_id") private String id; }
}
public static void main(String[] args) { save(); find(); emf.close(); }
private static void find() { logic(em -> { A a = em.find(A.class, "A_ID"); BId bId = new B.BId(); bId.setAId("A_ID"); bId.setId("B_ID"); B b = em.find(B.class, bId); CId cId = new C.CId(); cId.setBId(bId); cId.setId("C_ID"); C c = em.find(C.class, cId); }); }
private static void save() { logic(em -> { A a = new A(); a.setId("A_ID"); a.setName("A"); em.persist(a); B b = new B(); b.setA(a); BId bId = new B.BId(); bId.setAId("A_ID"); bId.setId("B_ID"); b.setId(bId); b.setName("B"); em.persist(b); C c = new C(); c.setB(b); CId cId = new C.CId(); cId.setBId(bId); cId.setId("C_ID"); c.setId(cId); c.setName("C"); em.persist(c); }); }
@EmbeddedId는 @IdClass와다르게 @Id 대신 @MapsId를사용한다.
@MapsId외래키와매핑한연관관계를기본키에도매핑하겠다는뜻
@IdClass, @EmbeddedId는엔티티에서매핑방식이기에 DB 테이블생성, 조회쿼리는똑같다.
비식별관계구현
@Entity @Data public class A { @Id @GeneratedValue @Column(name = "a_id") private Long id; private String name;; }
@Entity @Data public class B { @Id @GeneratedValue @Column(name = "b_id") private Long id; @ManyToOne @JoinColumn(name = "a_id") private A a; private String name;; }
@Entity @Data public class C { @Id @GeneratedValue @Column(name = "c_id") private Long id; @ManyToOne @JoinColumn(name = "b_id") private B b; private String name; }
비식별관계에서복합키를만들필요가없어식별관계사용시복합키를사용한것과비교해더쉽다.
일대일식별관계
일대일관계는자식테이블이부모테이블기본키를외래키 + 기본키로사용한다.
따라서부모테이블기본키가복합키가아니면, 자식테이블도복합키로구성하지않아도된다.
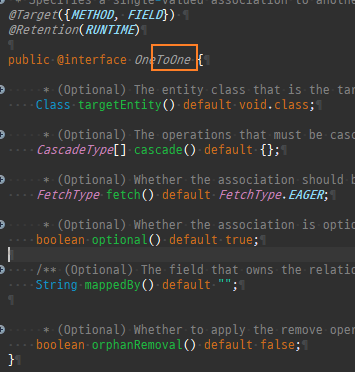
@Entity @Data public class Board { @Id @GeneratedValue @Column(name = "board_id") private Long id; private String title; @OneToOne(mappedBy = "board") private BoardDetail boardDetail; }
@Entity @Data public class BoardDetail { @Id private Long id; @MapsId @OneToOne @JoinColumn(name = "board_id") private Board board; private String content; }
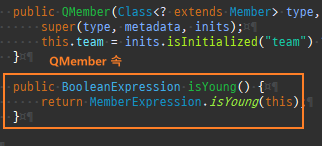
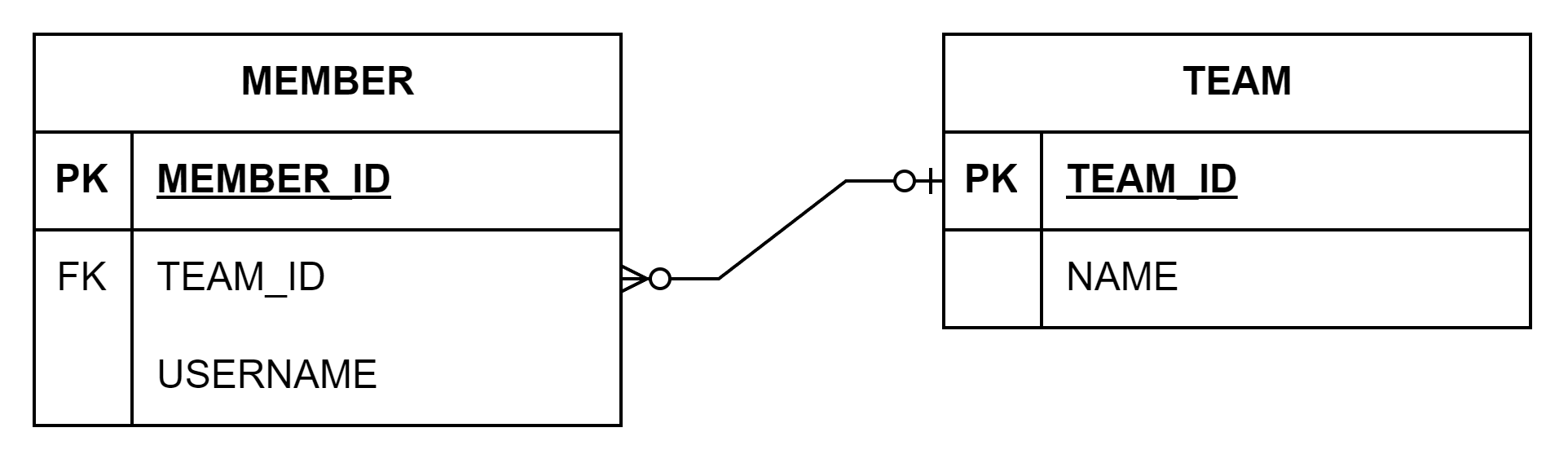
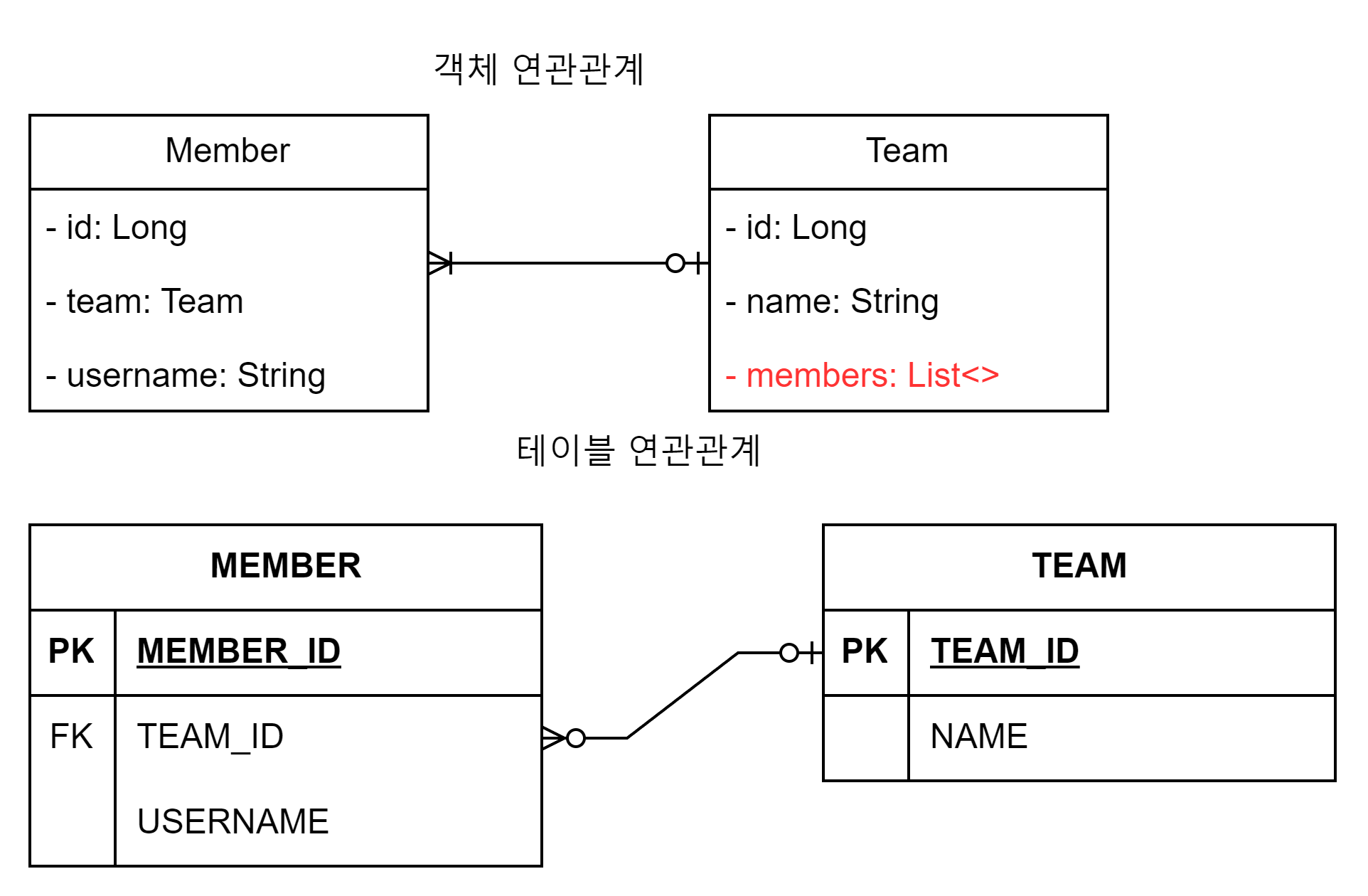
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String username; @ManyToOne @JoinColumn(name = "team_id") private Team team; }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Team { @Id @GeneratedValue @Column(name = "team_id") private Long id; private String name; }
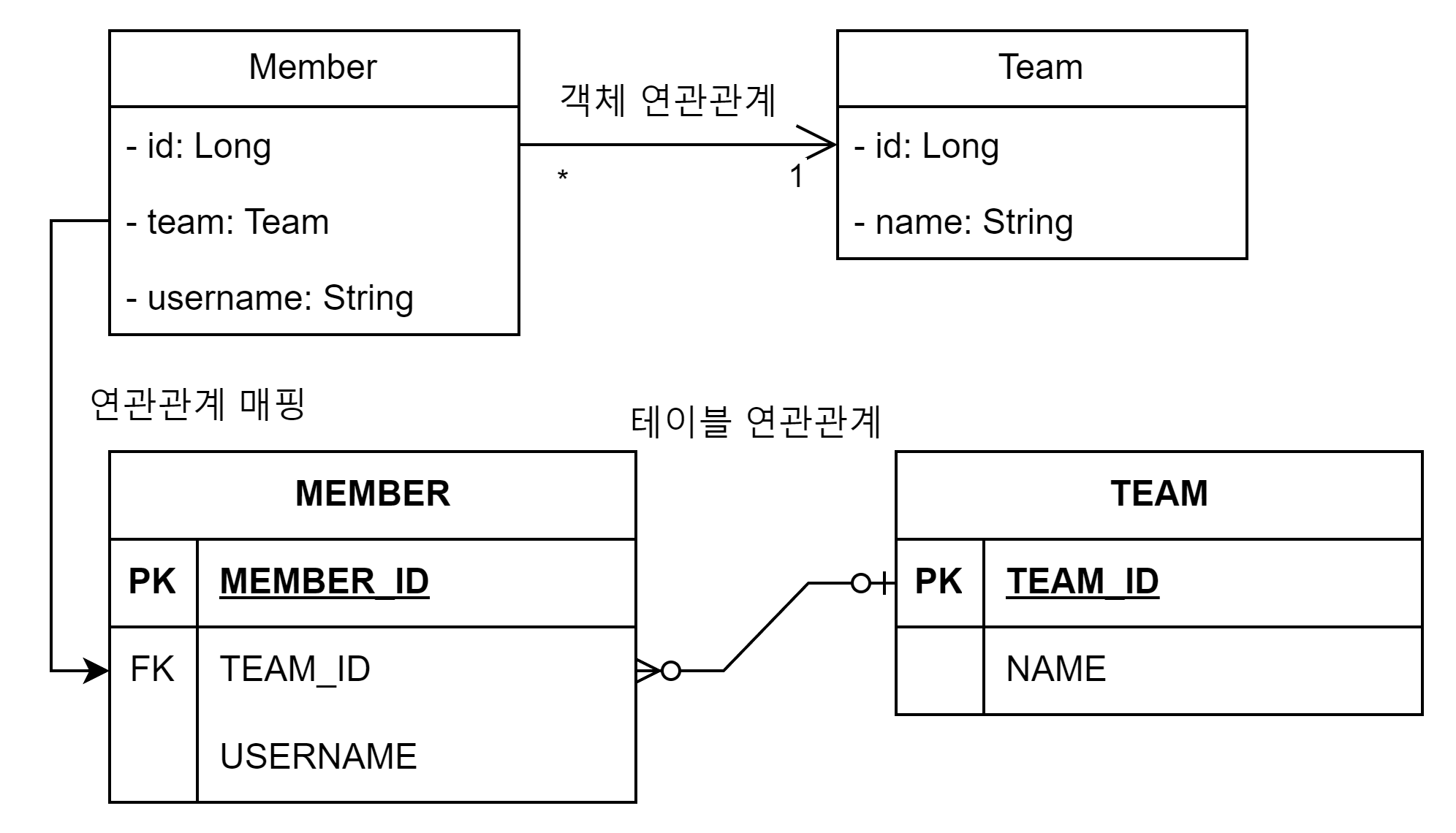
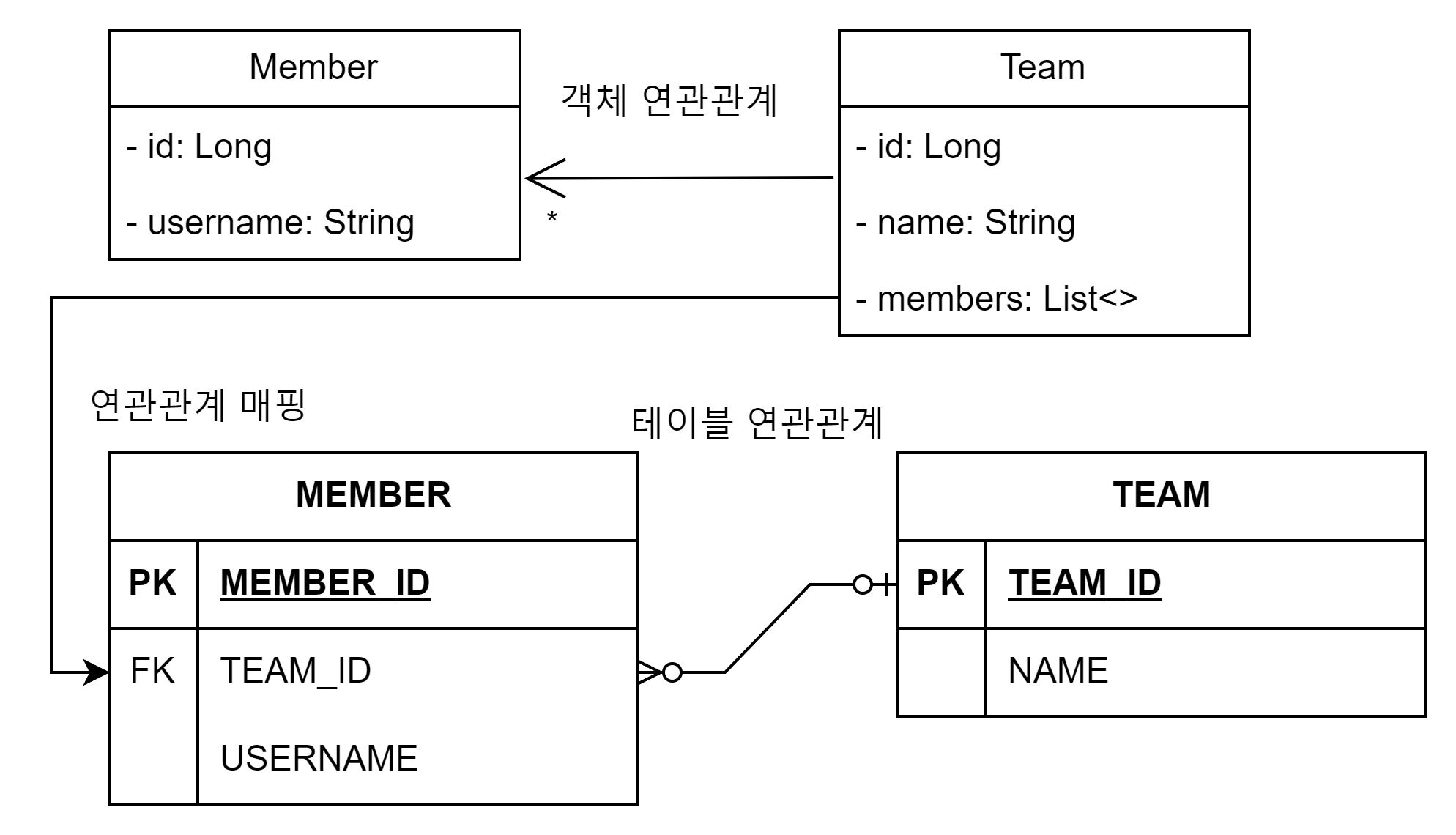
Member 에서 Team 만탐색이가능
다대일양방향
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private String id; private String username; @ManyToOne @JoinColumn(name = "team_id") private Team team; public void setTeam(Team team) { // 최초 값 할당 시 null 체크 if (this.team != null) { team.getMembers().remove(this); } this.team = team; // 내가 이미 저장되어 있는지 (루프 체크) if (!team.getMembers().contains(this)) { team.getMembers().add(this); } } }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Team { @Id @GeneratedValue @Column(name = "team_id") private String id; private String name; @OneToMany(mappedBy = "team") private List<Member> members = new ArrayList<>(); public void addMember(Member member) { this.members.add(member); // 내가 이미 연관관계 맺고 있는지 (루프 방지) if (member.getTeam() != this) { member.setTeam(this);; } } }
private static void save() { logic(em -> { Member m1 = new Member(); m1.setUsername("m1"); Member m2 = new Member(); m2.setUsername("m2"); Team t1 = new Team(); t1.getMembers().add(m1); t1.getMembers().add(m2); em.persist(m1); em.persist(m2); em.persist(t1); // 문제 지점 }); }
Member 엔티티는 Team 엔티티를모른다.
그러나연관관계에대한정보는 Team.members 가관리한다.
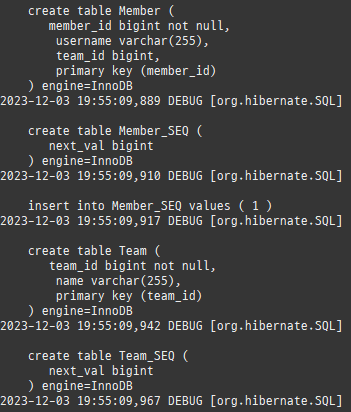
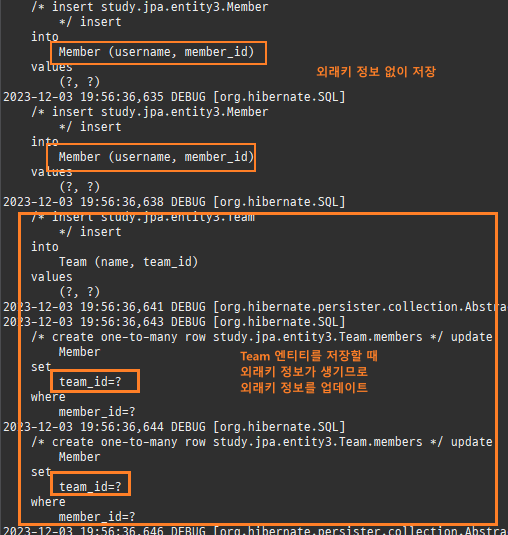
따라서 Member 엔티티를저장할때는외래키정보가빠지고저장한다.
나중에 Team 엔티티를저장할때 Team.members의참조값을확인하고 Member 테이블의외래키정보를업데이트한다.
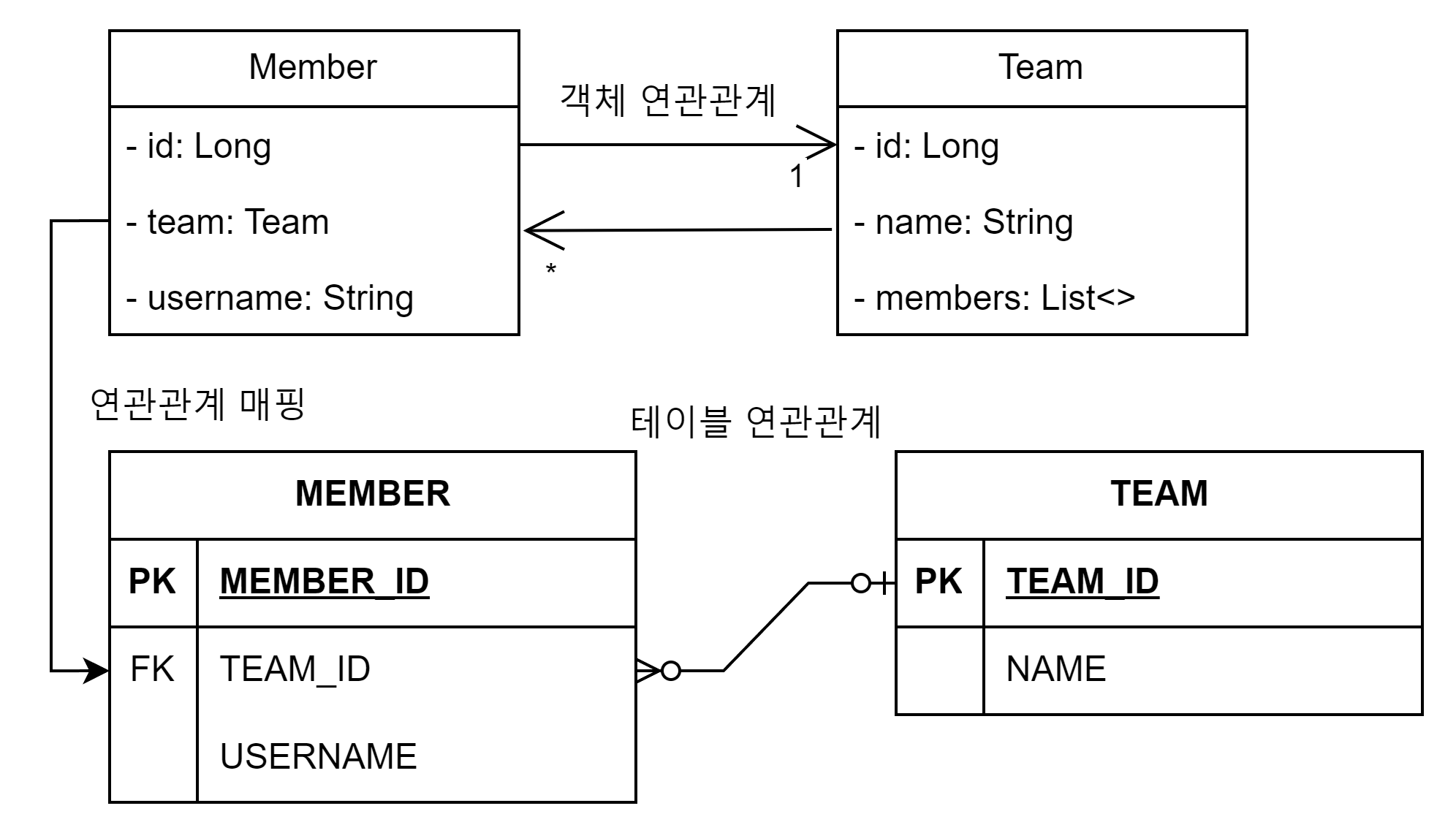
일대다양방향
일대다양방향매핑은없다.
양방향매핑에서 @OneToMany는연관관계의주인이될수없다.
RDB 특성상일대다관계에선외래키는항상다쪽에있다.
일대다 : 다대일관계에서항상다대일쪽이연관관계주인일수밖에없다.
그런이유로 ManyToOne은 mappedBy 속성이없다.
억지로사용할려면사용할수있다.
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String username; @ManyToOne @JoinColumn(name = "team_id", insertable = false, updatable = false) private Team team; }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Team {
@Id @GeneratedValue @Column(name = "team_id") private Long id; private String name; @OneToMany @JoinColumn(name = "team_id") // Member 테이블의 team_id 컬럼을 의미함 private List<Member> members = new ArrayList<>(); }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; @OneToOne @JoinColumn(name = "locker_id") private Locker locker; private String username; }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Locker { @Id @GeneratedValue @Column(name = "locker_id") private Long id; private String name; }
양방향
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Locker { @Id @GeneratedValue @Column(name = "locker_id") private Long id; private String name; @OneToOne(mappedBy = "locker") private Member member; }
연관관계의주인만정해주면된다.
대상테이블에외래키
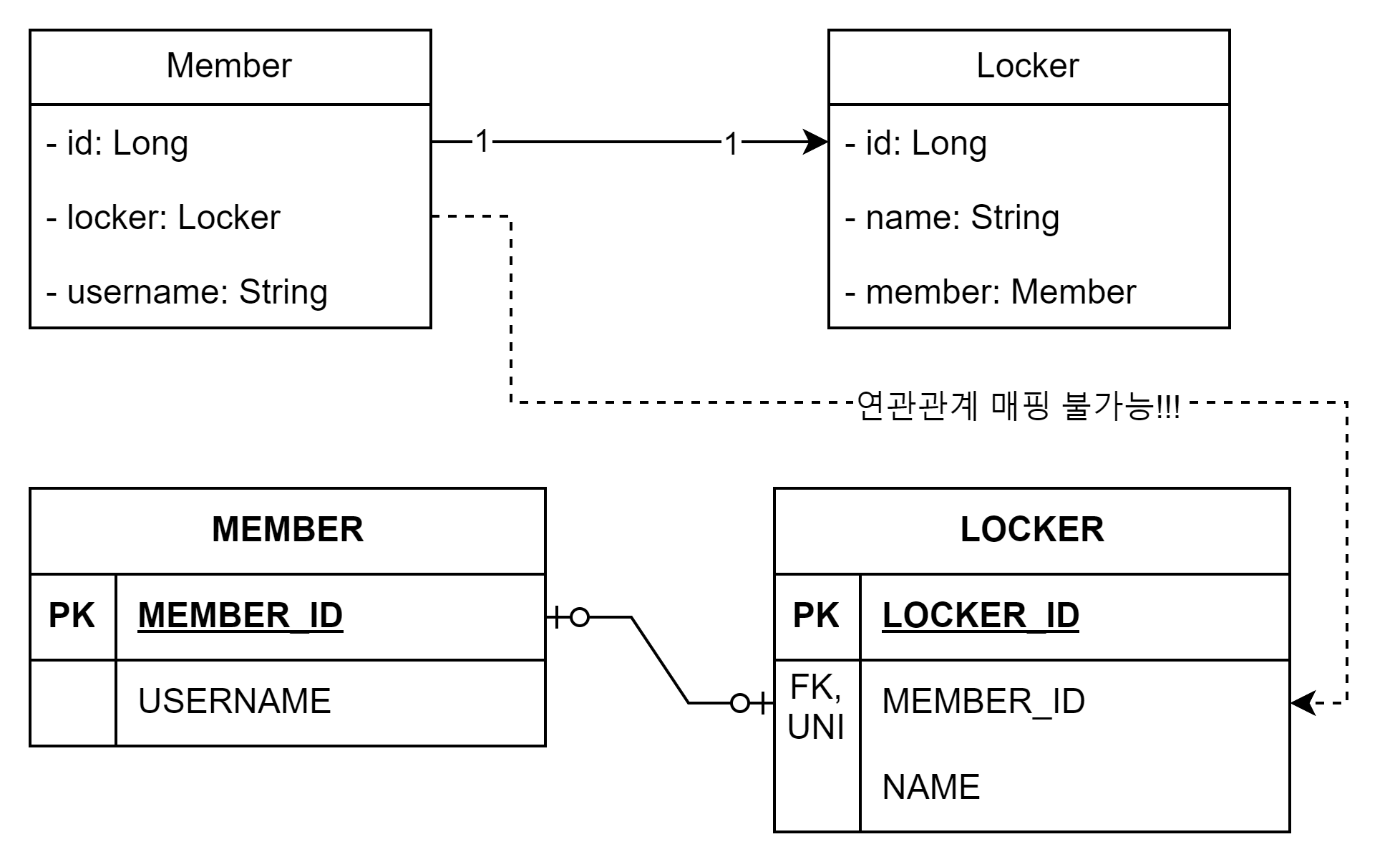
단방향
일대일관계중주엔티티에서대상테이블에외래키가있는단방향관계는 JPA에서지원하지않는다.
매핑할수있는방법이없다. 하려면양방향으로바꿔야한다.
양방향
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; @OneToOne(mappedBy = "member") private Locker locker; private String username; }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Locker { @Id @GeneratedValue @Column(name = "locker_id") private Long id; private String name; @OneToOne @JoinColumn(name = "member_id") private Member member; }
일대일매핑에서대상테이블에외래키를두고싶으면, 양방향으로매핑해야한다.
주엔티티인 Member 엔티티대신대상엔티티 Locker를연관관계의주인으로만들어 Locker의외래키 member_id를관리하게한다.
다대다
RDB는정규화된두테이블로다대다관계를표현할수없다.
그래서중간에연결테이블을추가해일대다-다대일, 일대다-다대일로해소한다.
다대다관계는테이블에서는불가능하지만, 객체관계에서는가능하다.
양쪽에서컬렉션을사용하면그만이다.
다대다단방향
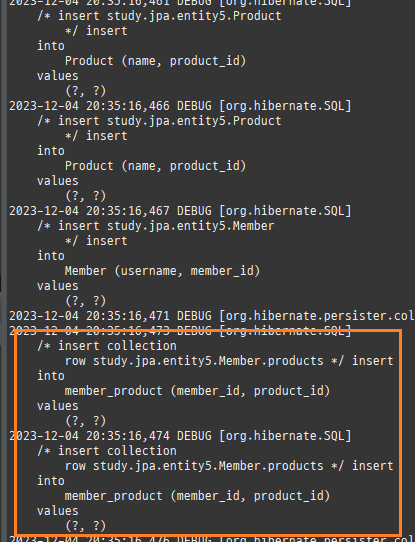
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String username; @ManyToMany @JoinTable(name = "member_product", joinColumns = @JoinColumn(name = "member_id"), inverseJoinColumns = @JoinColumn(name = "product_id")) private List<Product> products = new ArrayList<>(); }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Product { @Id @GeneratedValue @Column(name = "product_id") private Long id; private String name; }
public class Main { static EntityManagerFactory emf = Persistence.createEntityManagerFactory("studyjpa"); public static void main(String[] args) { save(); find(); emf.close(); }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String username; @ManyToMany @JoinTable(name = "member_product", joinColumns = @JoinColumn(name = "member_id"), inverseJoinColumns = @JoinColumn(name = "product_id")) private List<Product> products = new ArrayList<>(); }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Product { @Id @GeneratedValue @Column(name = "product_id") private Long id; private String name; @ManyToMany(mappedBy = "products") @ToString.Exclude // toString 무한 루프 방지 private List<Member> members; }
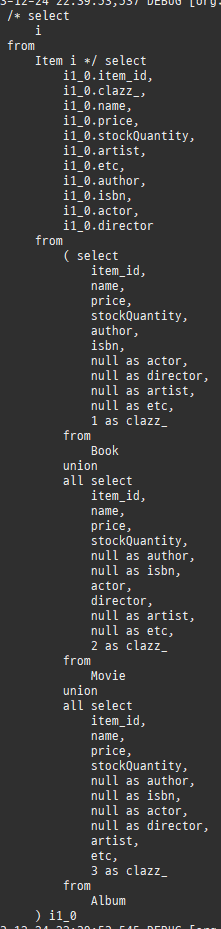
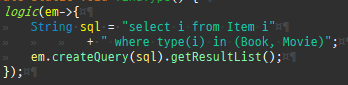
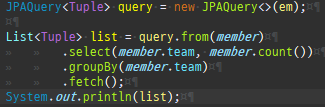
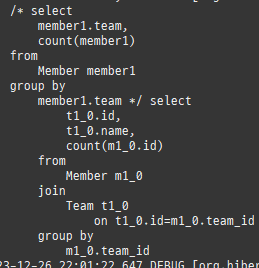
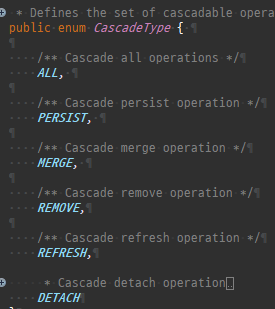
다대다매핑의한계와극복, 연결엔티티사용
@ManyToMany 로연결테이블을자동으로처리할수있지만, 실무에서사용하기엔한계가있다.
실무라면, 연결테이블에멤버ID, 상품ID로끝나지않는다.
추가정보가더담긴다.
@ManyToMany 로는추가정보를담을수없다.
따로연결테이블을매핑하는연결엔티티를만들고, 거기에추가컬럼을매핑해야한다.
사실지금 DDL AUTO 기능은실무에선쓰지못한다.
신규기능개발할때나독립적으로사용한다.
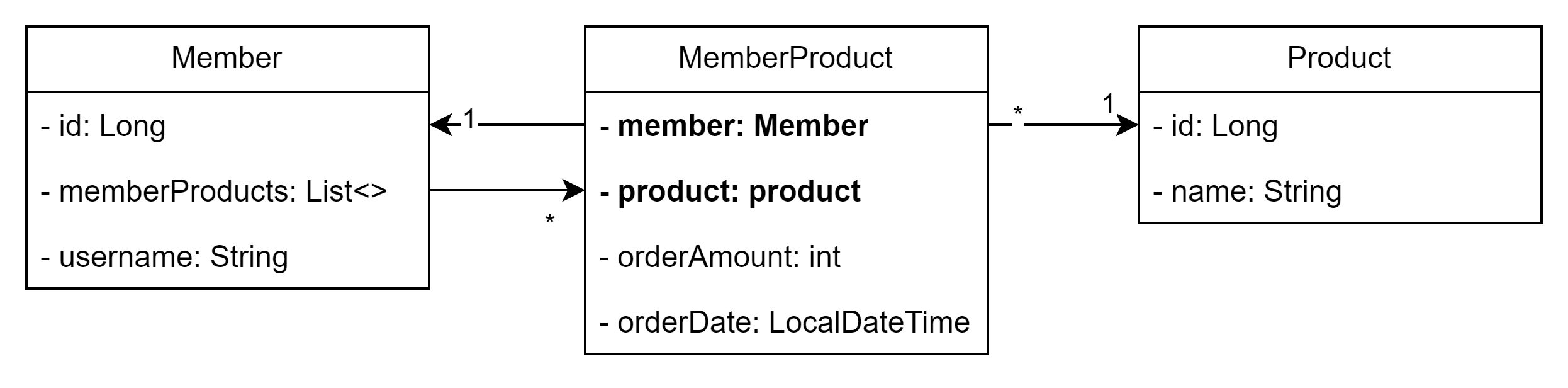
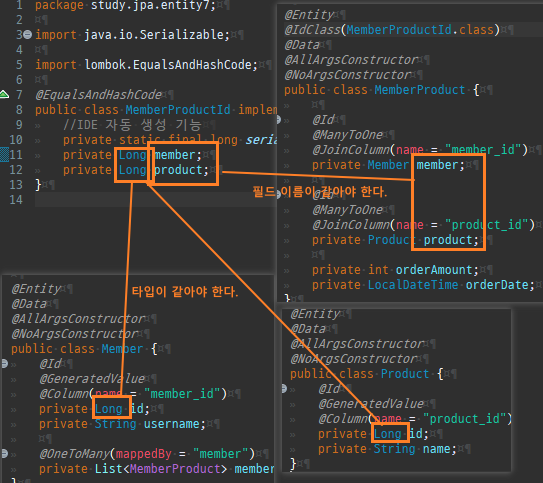
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @GeneratedValue @Column(name = "member_id") private Long id; private String username; @OneToMany(mappedBy = "member") private List<MemberProduct> memberProducts = new ArrayList<>(); }
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Product { @Id @GeneratedValue @Column(name = "product_id") private Long id; private String name; }
@Entity @IdClass(MemberProductId.class) @Data @AllArgsConstructor @NoArgsConstructor public class MemberProduct { @Id @ManyToOne @JoinColumn(name = "member_id") private Member member; @Id @ManyToOne @JoinColumn(name = "product_id") private Product product; private int orderAmount; private LocalDateTime orderDate; }
@EqualsAndHashCode public class MemberProductId implements Serializable{ //IDE 자동 생성 기능 private static final long serialVersionUID = 938018879231292890L; private Long member; private Long product; }
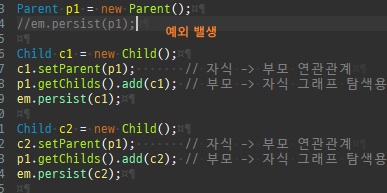
private static void save() { logic(em -> { Team t1 = new Team("team1", "팀1"); em.persist(t1); Member m1 = new Member("member1", "멤버1"); m1.setTeam(t1); em.persist(m1); Member m2 = new Member("member2", "멤버2"); m2.setTeam(t1); em.persist(m2); }); }
양방향연관관계주의점
연관관계의주인이아님
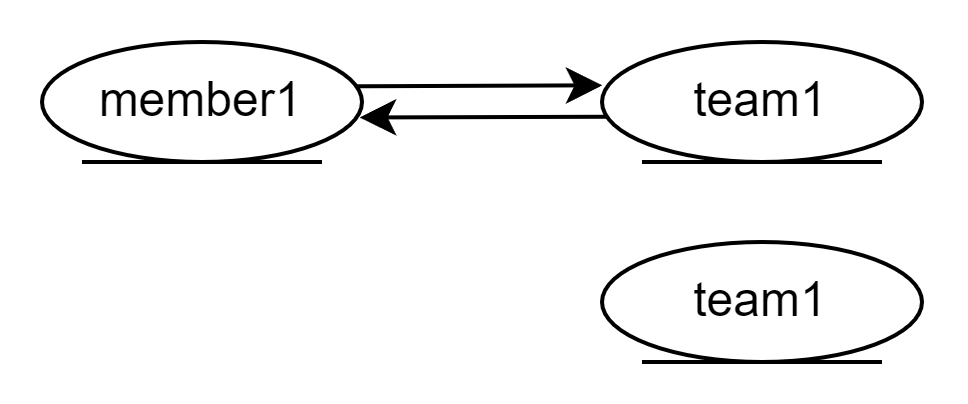
private static void save2() { logic(em -> { Member m1 = new Member("member1", "멤버1"); em.persist(m1); Member m2 = new Member("member2", "멤버2"); em.persist(m2); //연관관계의 주인이 아닌곳에서 저장 Team t1 = new Team("team1", "팀1"); t1.getMembers().add(m1); t1.getMembers().add(m2); em.persist(t1); }); }
순수한객체까지고려한양방향연관관계
객체관점에서양쪽방향에서모두값을입력해주는것이안전하다.
JPA는자바 ORM 표준으로객체와 RDB 모두중요하다.
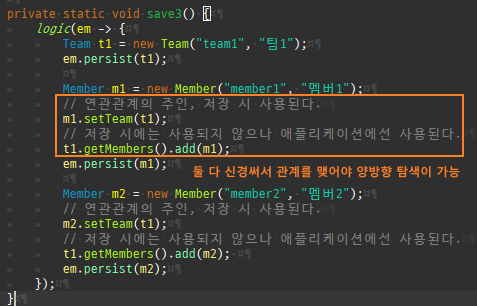
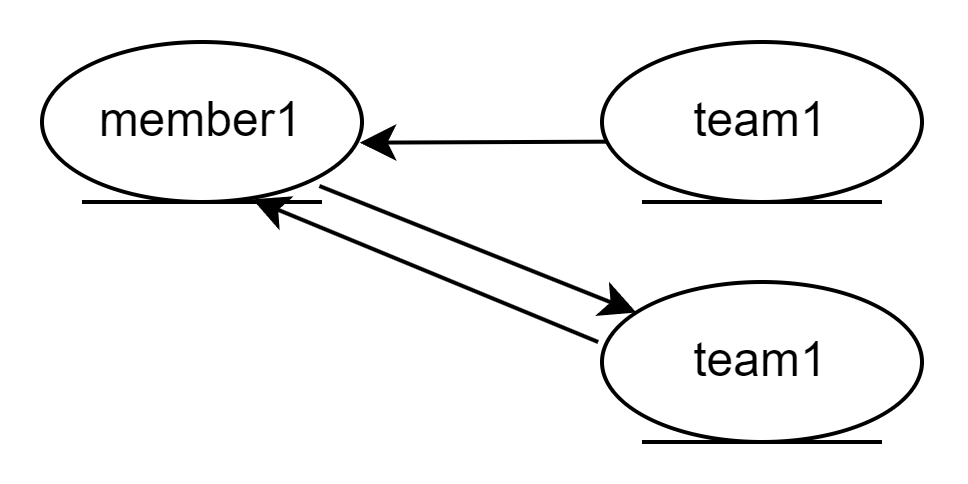
private static void save3() { logic(em -> { Team t1 = new Team("team1", "팀1"); em.persist(t1); Member m1 = new Member("member1", "멤버1"); // 연관관계의 주인, 저장 시 사용된다. m1.setTeam(t1); // 저장 시에는 사용되지 않으나 애플리케이션에선 사용된다. t1.getMembers().add(m1); em.persist(m1); Member m2 = new Member("member2", "멤버2"); // 연관관계의 주인, 저장 시 사용된다. m2.setTeam(t1); // 저장 시에는 사용되지 않으나 애플리케이션에선 사용된다. t1.getMembers().add(m2); em.persist(m2); }); }
연관관계편의메소드
양방향연관관계는기존단방향에더해추가단방향까지신경써야한다.
전부호출해야양방향이된다.
실수로하나란호출하면양방향이깨진다.
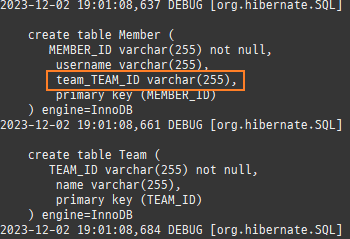
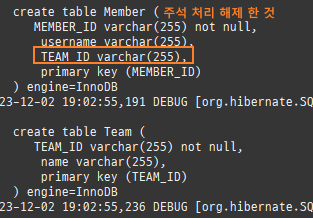
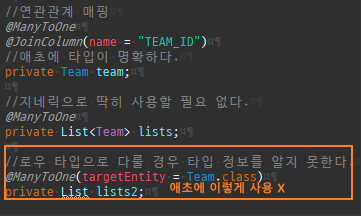
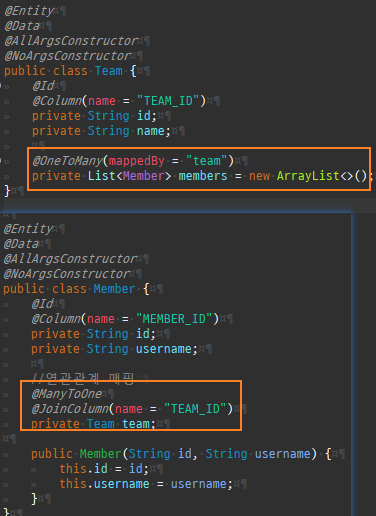
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Member { @Id @Column(name = "MEMBER_ID") private String id; private String username; //연관관계 매핑 @ManyToOne @JoinColumn(name = "TEAM_ID") private Team team;
// 연관관계 편의 메서드 리팩터링 저장 private static void save4() { logic(em -> { Team t1 = new Team("team1", "팀1"); em.persist(t1); Member m1 = new Member("member1", "멤버1"); // 연관관계의 주인, 저장 시 사용된다. m1.setTeam(t1); // 저장 시에는 사용되지 않으나 애플리케이션에선 사용된다. // t1.getMembers().add(m1); em.persist(m1); Member m2 = new Member("member2", "멤버2"); // 연관관계의 주인, 저장 시 사용된다. m2.setTeam(t1); // 저장 시에는 사용되지 않으나 애플리케이션에선 사용된다. // t1.getMembers().add(m2); em.persist(m2); }); }
한번에양방향관계를설정하는메소드를연관관계편의메소드라한다.
연관관계편의메소드작성시주의사항
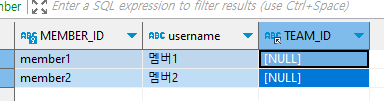
// 연관관계 편의 메서드 주의사항 private static void save5() { logic(em -> { Team t1 = new Team("team1", "팀1"); em.persist(t1); Team t2 = new Team("team2", "팀2"); em.persist(t2); Member m1 = new Member("member1", "멤버1"); m1.setTeam(t1); m1.setTeam(t2); em.persist(m1); // t1 은 여전히 멤버1을 가지고 있다. 물론 // 연관관계의 주인이 아니라 DB에 영향은 없지만, // 문제가 있다. t1.getMembers().forEach(m -> { System.out.println(m.getUsername()); }); }); }
team1 -> member1 은연관관계편의메서드가처리한것
연관관계편의메서드에서신규관계만집중한나머지남겨질관계를신경쓰지못한모습
public void setTeam(Team team) { // 기존 팀에 나의 관계를 지움 if (this.team != null) { this.team.getMembers().remove(this); } this.team = team; //편의 메서드 team.getMembers().add(this); }
// 연관관계 편의 메서드 주의사항 private static void save5() { logic(em -> { Team t1 = new Team("team1", "팀1"); em.persist(t1); Team t2 = new Team("team2", "팀2"); em.persist(t2); Member m1 = new Member("member1", "멤버1"); m1.setTeam(t1); m1.setTeam(t2); em.persist(m1); // t1 은 여전히 멤버1을 가지고 있다. 물론 // 연관관계의 주인이 아니라 DB에 영향은 없지만, // 문제가 있다. System.out.println("##################"); t1.getMembers().forEach(m -> { System.out.println(m.getUsername()); }); }); }
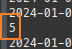
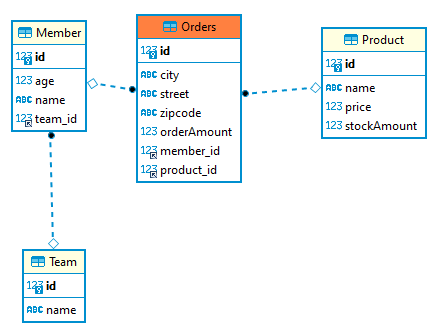
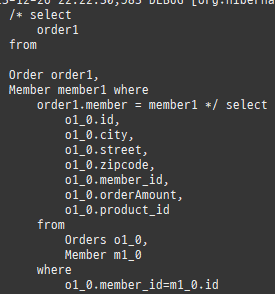
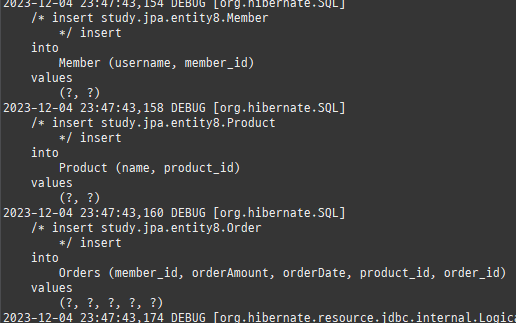
@Entity @Data public class Member { @Id @GeneratedValue @Column(name = "MEMBER_ID") private Long id; private String name; private String city; private String strret; private String zipcode; @OneToMany(mappedBy = "member") @ToString.Exclude private List<Order> orders = new ArrayList<>(); }
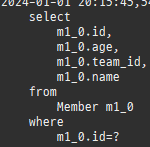
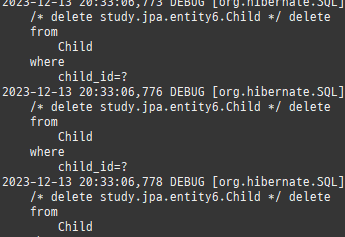
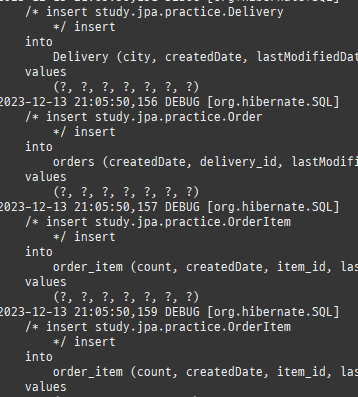
@Entity @Table(name = "ORDERS") @Data public class Order { @Id @GeneratedValue @Column(name = "ORDER_ID") private Long id; @ManyToOne @JoinColumn(name = "MEMBER_ID") private Member member; @OneToMany(mappedBy = "order") private List<OrderItem> orderItems = new ArrayList<>(); private LocalDateTime orderDate; @Enumerated(EnumType.STRING) private OrderStatus status; // 연관관계 편의 메소드 public void setMember(Member member) { if (this.member != null) { this.member.getOrders().remove(this); } this.member = member; member.getOrders().add(this); } public void addOrderItem(OrderItem orderItem) { orderItems.add(orderItem); orderItem.setOrder(this); } }
public enum OrderStatus { ORDER, CANCEL }
@Entity @Table(name = "ORDER_ITEM") @Data public class OrderItem { @Id @GeneratedValue @Column(name = "ORDER_ITEM_ID") private Long id; @ManyToOne @JoinColumn(name = "ITEM_ID") private Item item;
@ManyToOne @JoinColumn(name = "ORDER_ID") private Order order; private int orderPrice; private int count; public void setOrder(Order order) { if (this.order != null) { this.order.getOrderItems().remove(this); } this.order = order; order.getOrderItems().add(this); } }
@Entity @Data public class Item { @Id @GeneratedValue @Column(name = "ITEM_ID") private Long id; private String name; private int price; private int stockQuantity; }
@Entity public class Member { @Id @Column(name = "MEMBER_ID") private Long id; private String name; // 생성자가 아무 것도 없으면, 컴파일러가 기본 생성자를 생성해준다. // 이렇게 생성자를 만들면, 컴파일러는 기본 생성자를 안만들어 준다. public Member(Long id, String name, Team team) { this.id = id; this.name = name; this.team = team; }
다른곳에서도기본생성자는필수있때가있다. 무조건기본생성자는만들어도나쁠건없다.
@Table
엔티티와테이블을매핑할때사용한다.
생략이가능하다. 생략시 @Entity 붙은클래스이름과같은테이블에매핑한다.
속성
기능
기본값
name
매핑할테이블이름
엔티티이름
catalog
catalog 있는 DB에서 catalog 매핑
schema
schema 있는 DB에서 schema 매핑
uniqueConstraints
유니크제약조건을추가한다. 자동 DDL 생성에서만사용한다. 실제실무에선 Table을직접만드므로사용할일이없다.
매핑정보
import java.util.Date;
import jakarta.persistence.*;
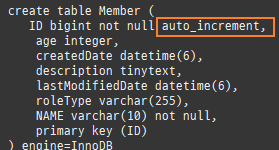
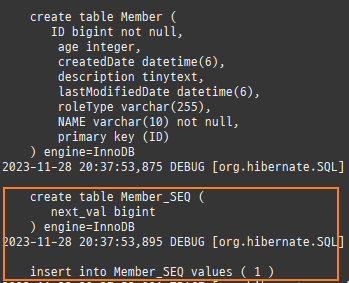
@Entity @Table(name = "MEMBER") public class Member { @Id @Column(name = "ID") private String id; @Column(name = "NAME") private String username; private Integer age; @Enumerated(EnumType.STRING) private RoleType roleType; @Temporal(TemporalType.TIMESTAMP) private Date createdDate; private Date lastModifiedDate; @Lob private String description;
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getUsername() { return username; }
public void setUsername(String username) { this.username = username; }
public Integer getAge() { return age; }
public void setAge(Integer age) { this.age = age; }
public RoleType getRoleType() { return roleType; }
public void setRoleType(RoleType roleType) { this.roleType = roleType; }
public Date getCreatedDate() { return createdDate; }
public void setCreatedDate(Date createdDate) { this.createdDate = createdDate; }
public Date getLastModifiedDate() { return lastModifiedDate; }
public void setLastModifiedDate(Date lastModifiedDate) { this.lastModifiedDate = lastModifiedDate; }
public String getDescription() { return description; }
public void setDescription(String description) { this.description = description; } }
public enum RoleType { ADMIN, USER }
DB 스키마자동생성
persistence.xml설정정보
<?xml version="1.0" encoding="utf-8"?> <persistence xmlns="https://jakarta.ee/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://jakarta.ee/xml/ns/persistencehttps://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd" version="3.0"> <persistence-unit name="studyjpa" transaction-type="RESOURCE_LOCAL"> <properties> <!-- DB 연결 정보 --> <property name="jakarta.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver" /> <property name="jakarta.persistence.jdbc.url" value="jdbc:mysql://localhost:55555/jpa?characterEncoding=utf8" /> <property name="jakarta.persistence.jdbc.user" value="root" /> <property name="jakarta.persistence.jdbc.password" value="root" /> <property name="hibernate.hikari.poolName" value="pool" /> <property name="hibernate.hikari.maximumPoolSize" value="10" /> <property name="hibernate.hikari.minimumIdle" value="10" /> <property name="hibernate.hikari.connectionTimeout" value="1000" /> <!-- MySql 방언 --> <property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect" /> <!-- SQL 출력 --> <!-- <property name="hibernate.show_sql" value="true" />--> <!-- SQL 이쁘게 출력 --> <property name="hibernate.format_sql" value="true" /> <!-- 주석도 함께 출력 --> <property name="hibernate.use_sql_comments" value="true" /> <!-- JPA 표준에 맞춘 새로운 키 생성 전략 사용 --> <property name="hibernate.id.new_generator_mappings" value="true" /> <!-- 실습에서만 사용할 것, @Entity에 따라 DDL 명령을 자동 실행해 준다. --> <property name="hibernate.hbm2ddl.auto" value="create" /> </properties> </persistence-unit> </persistence>
Caused by: org.hibernate.MappingException: The increment size of the [MEMBER_SEQ] sequence is set to [20] in the entity mapping while the associated database sequence increment size is [1]. at org.hibernate.id.enhanced.SequenceStyleGenerator.configure(SequenceStyleGenerator.java:218) at org.hibernate.id.factory.internal.StandardIdentifierGeneratorFactory.createIdentifierGenerator(StandardIdentifierGeneratorFactory.java:217) ... 19 more
DDL 자동생성기능을꺼도, allocationSize는사용되는유효한값이다.
allocationSize기본값이 50 인이유
시퀀스전략은 INSERT 시 DB와두번통신한다고했다.
이를줄이기위한최적화방법으로시퀀스는 50씩증가시킨다.
한번시퀀스를조회하고, 다음번시퀀스증가크기만큼메모리에서시퀀스를처리한다.
즉, 50 번 INSERT 마다시퀀스를한번조회한다.
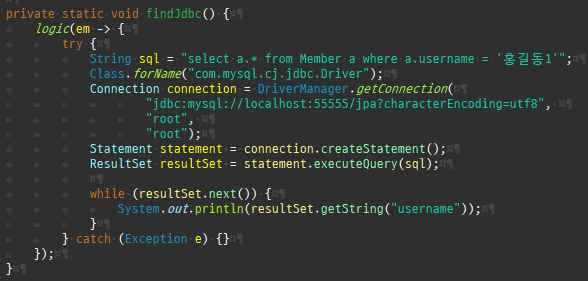
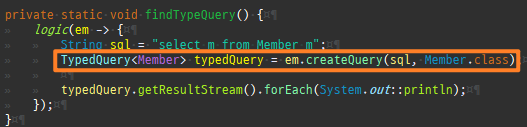
Member member = null; for (int i = 0; i < 50; i++) { member = new Member(); member.setUsername("홍길동" + i); em.persist(member); }
한번의시퀀스조회로 50 까지식별자를메모리에서할당한것을볼수있다.
보통은allocationSize값을 1로주고쓴다.
테이블전략
키생성전용테이블을만들고시퀀스를흉내낸다.
테이블전략도allocationSize 속성값으로최적화를진행할수있다.
로우하나가하나의시퀀스오브젝트를흉내낸다.
@TableGenerator
속성
기능
기본값
name
테이블식별자생성기이름
필수
table
DB 테이블명
pkColumnName
시퀀스컬럼명, 시퀀스오브젝트이름이라고봐도된다.
valueColumnValue
시퀀스값컬럼명
initialValue
초기값
0
allocationSize
한번호출시증가값
50
catalog, schema
uniqueConstraints
유니크제약조건지정(테이블이라가능한속성)
AUTO 전략
선택한 DB 방언에따라TABLE, SEQUENCE, IDENTITY중하나를자동으로선택
참고로기본값은 AUTO다
참고
기본키매핑정리
직접할당
DB 통신은플러시시점한번만이뤄진다.
SEQUENCE
시퀀스채번을위해 persist() 시점에 DB 통신, 플러시시점에 DB 통신
TABLE
시퀀스와똑같은이유로 DB와두번통신
IDENTITY
DB에게위임 Mysql의경우무조건데이터저장시키가생성되기에 persit() 시점에 INSERT 가이뤄진다.
@Entity @Data public class Member { @Id @GeneratedValue @Column(name = "MEMBER_ID") private Long id; private String name; private String city; private String strret; private String zipcode; }
@Entity @Table(name = "ORDERS") @Data public class Order { @Id @GeneratedValue @Column(name = "ORDER_ID") private Long id; @Column(name = "MEMBER_ID") private Long memberId; private LocalDateTime orderDate; @Enumerated(EnumType.STRING) private OrderStatus status; }
public enum OrderStatus { ORDER, CANCEL }
@Entity @Table(name = "ORDER_ITEM") @Data public class OrderItem { @Id @GeneratedValue @Column(name = "ORDER_ITEM_ID") private Long id; @Column(name = "ITEM_ID") private Long itemId; @Column(name = "ORDER_ID") private Long orderId; private int orderPrice; private int count; }
@Entity @Data public class Item { @Id @GeneratedValue @Column(name = "ITEM_ID") private Long id; private String name; private int price; private int stockQuantity; }
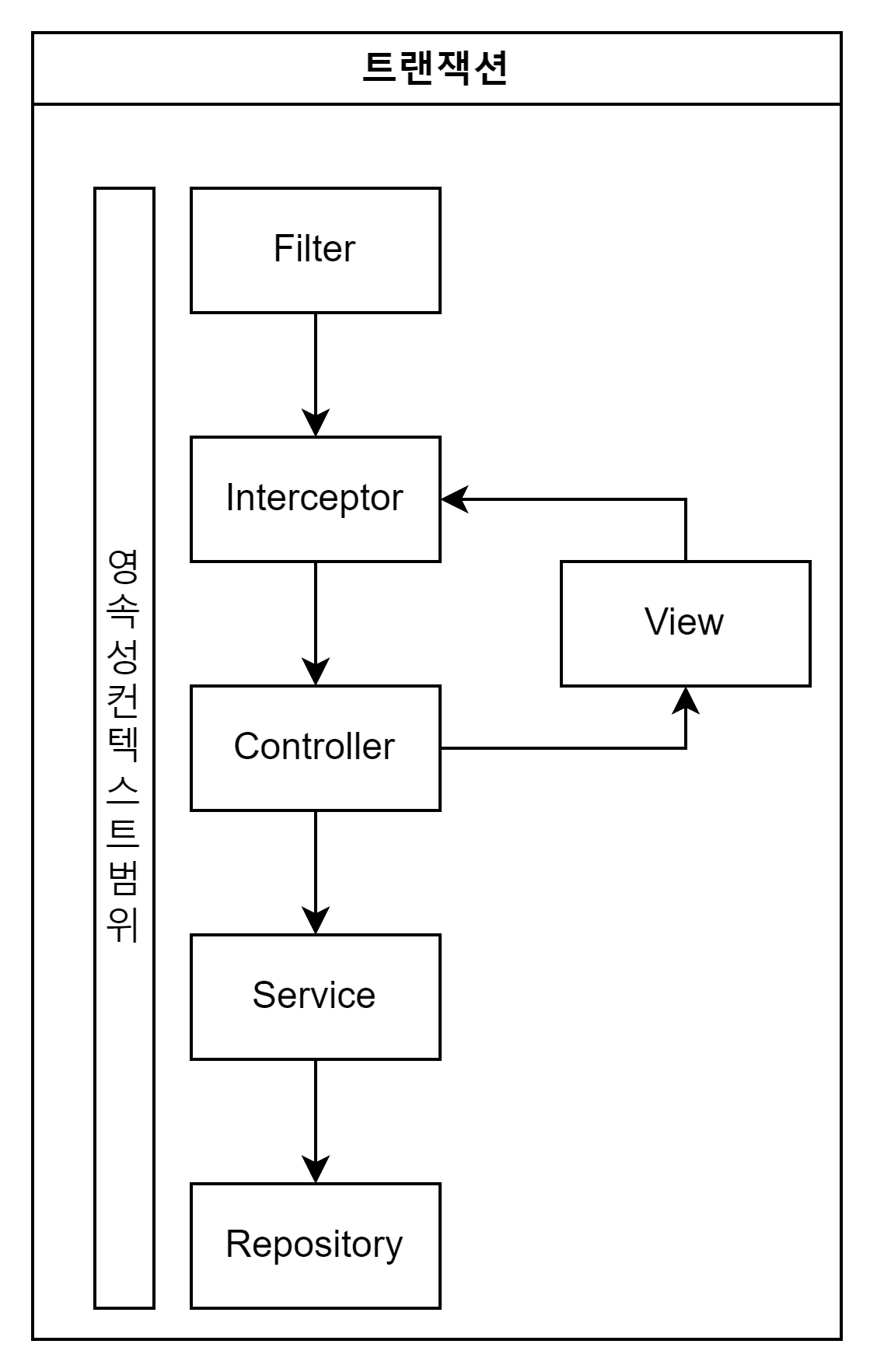
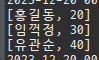
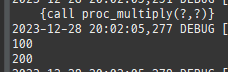
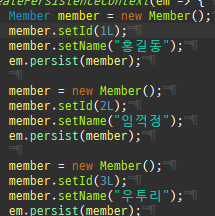
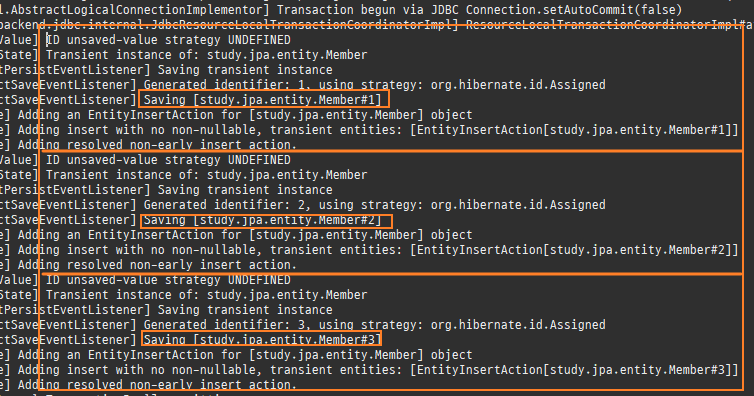
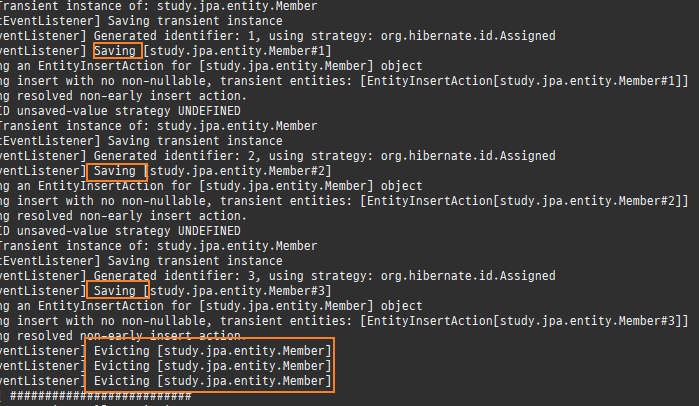
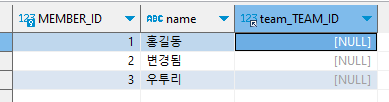
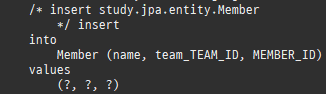
private static void createPersistenceContext(Consumer<EntityManager> consumer) { EntityManager em = emf.createEntityManager(); EntityTransaction tx = em.getTransaction(); try { tx.begin(); consumer.accept(em); logger.info("###################### 커밋 ##########################"); tx.commit(); } catch (Exception e) { tx.rollback(); } finally { em.close(); } } private static void save() { createPersistenceContext(em -> { Member member = new Member(); member.setId(1L); member.setName("홍길동"); em.persist(member); member = new Member(); member.setId(2L); member.setName("임꺽정"); em.persist(member); member = new Member(); member.setId(3L); member.setName("우투리"); em.persist(member); }); }
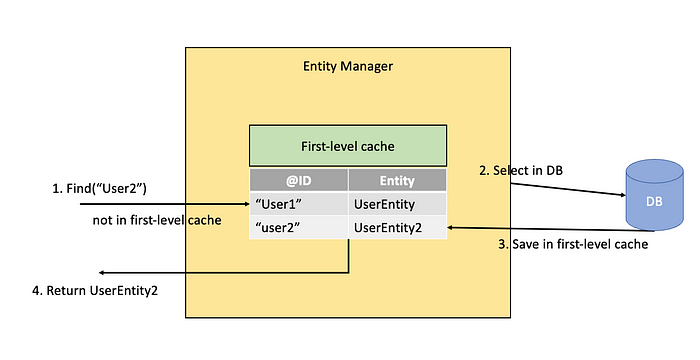
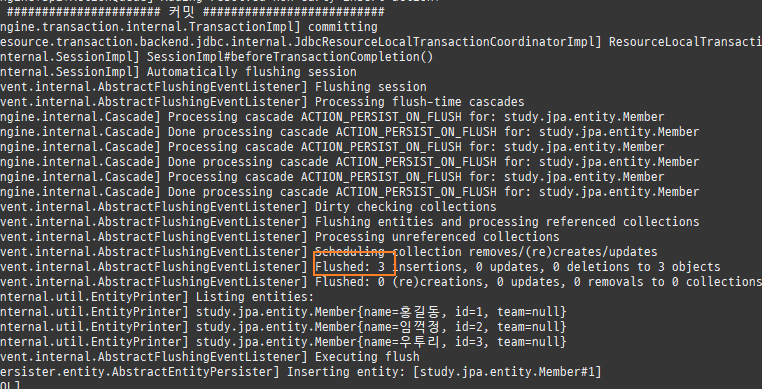
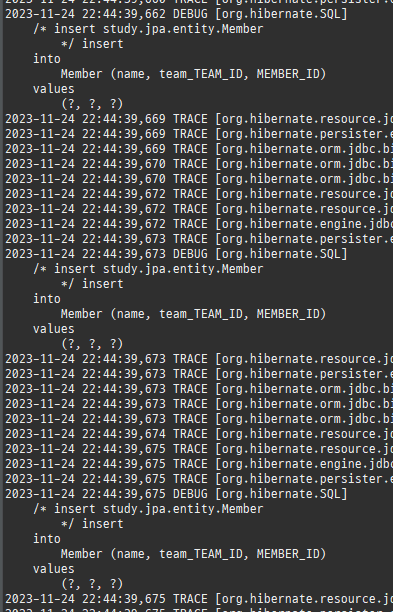
persist()호출을하면, DB에바로저장하는것이아니라작업큐에 SQL을저장해둔다.
그리고영속성컨텍스트에저장한다.
이후트랜잭션커밋시 DB와동기화된다.
쓰기지연은물리적 데이터베이스 트랜잭션이짧아져데이터베이스의 잠금 경합이줄어드는효과가있다.
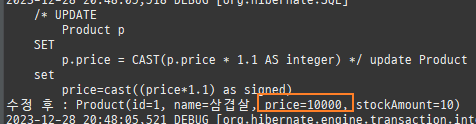
수정 (변경감지)
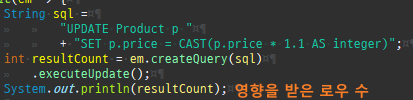
SQL 직접사용문제점
일반적으로직접 SQL로 Update 문을작성할시비즈니스요구사항이변경되추가되는컬럼이생기면, 따로 Update 문을더만들거나기존 Update 문을변경해야한다.
SQL에직간접적으로의존하게된다.
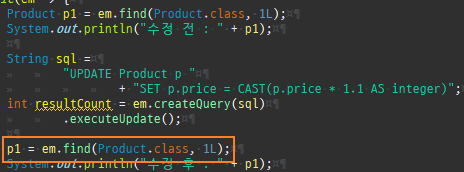
JPA 수정
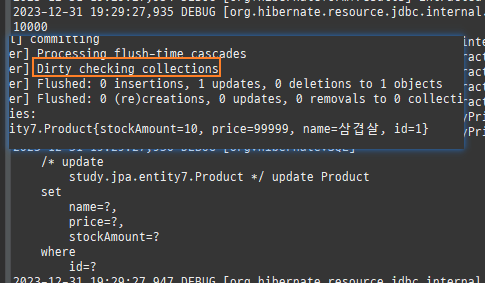
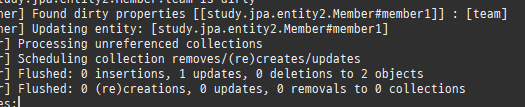
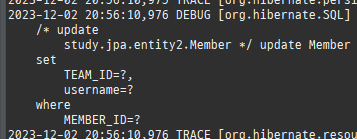
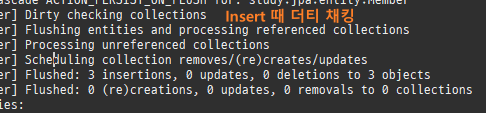
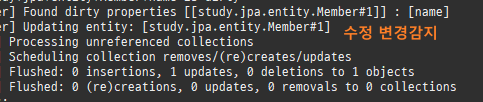
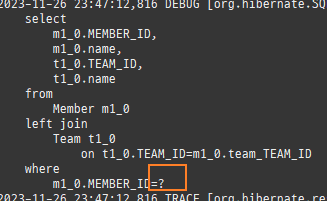
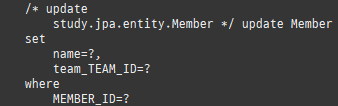
엔티티를조회후값을변경하면알아서 DB에반영이된다. 이를변경감지라한다.
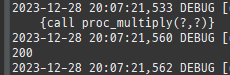
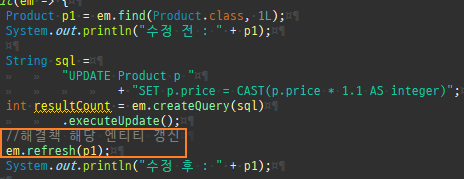
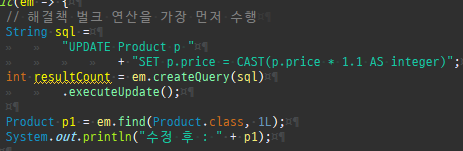
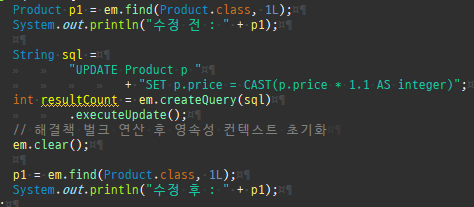
private static void update() { createPersistenceContext(em -> { Member m = em.find(Member.class, 1L); m.setName("아무개"); }); }
참고용
수정변경감지
엔티티를최초영속성컨텍스트에저장할때그상태를스냅샷으로저장을한다.
그리고플러시시점에서스냅샷을기반으로달라진엔티티를찾아업데이트를한다.
변경감지는이처럼영속성컨텍스트가관리하는상태에만적용된다.
private static void update() { createPersistenceContext(em -> { Member m = em.find(Member.class, 1L); m.setName("아무개"); em.detach(m); // 영속성 컨텍스트에서 분리하면, 업데이트 반영 안됨 }); }
JPA 수정알아둘것
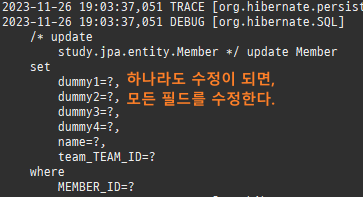
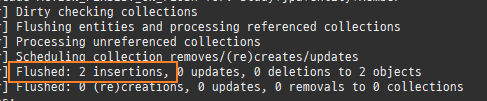
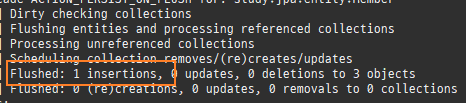
하나의변경이라도, 모든필드를수정한다.
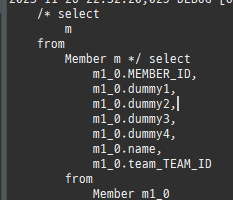
@Entity public class Member { @Id // @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "MEMBER_ID") private Long id; private String name; //주의사항을 알기 위해 일부러 필드 추가 private String dummy1; private String dummy2; private String dummy3; private String dummy4;
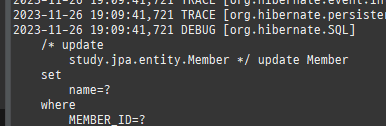
@Entity @DynamicUpdate public class Member { @Id // @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "MEMBER_ID") private Long id; private String name; //주의사항을 알기 위해 일부러 필드 추가 private String dummy1; private String dummy2; private String dummy3; private String dummy4;
일반적으로 30개이하면, 정적수정쿼리가더빠르다.
참고로테이블컬럼이 30개이상인경우는테이블설계가잘못되었을가능성이높다.
보통정적으로사용하다, 성능이슈가나오면동적으로사용하면된다.
삭제
Member m = em.find(Member.class, 1L); em.remove(m);
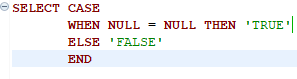
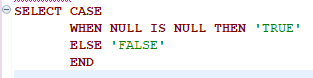
//준영속 상태 엔티티를 줘서 새로운 영속 상태 엔티티를 받는다. m1 = em.merge(m1); //merge()호출 전에 값을 바꿔도 상관 없다. flush() 시 바뀐 값으로 DB에 반영된다. m3.setName("우투리2"); //주의, 반환 객체를 반드시 사용해야 한다. em.merge(m2); m3 = em.merge(m3);








































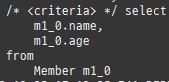
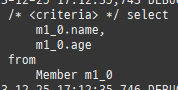
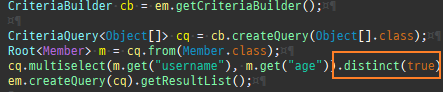
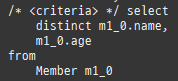
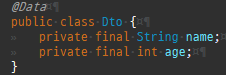
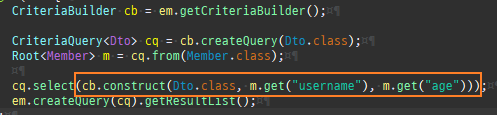
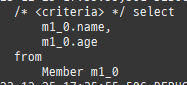
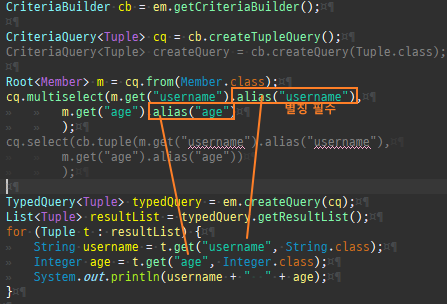
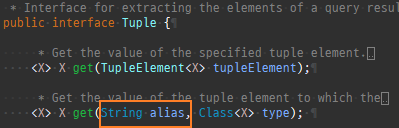
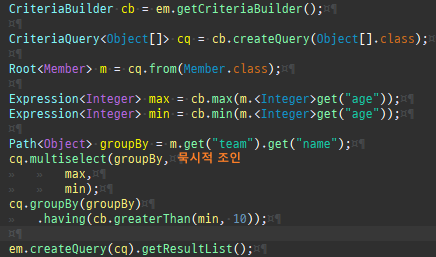



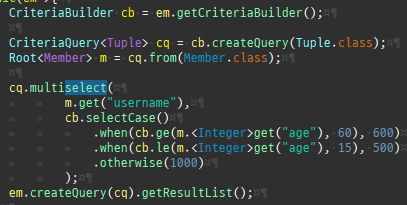
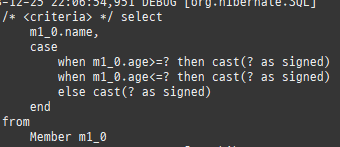
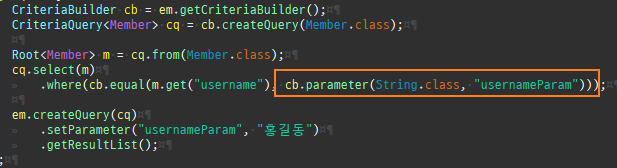
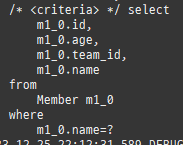
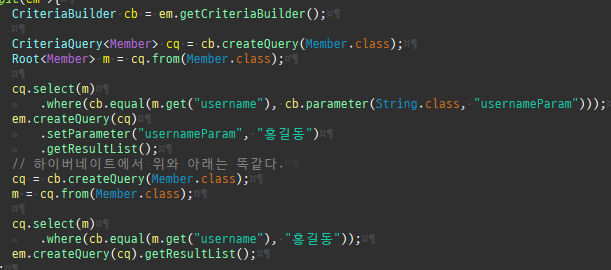
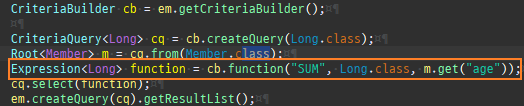
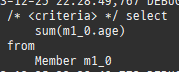
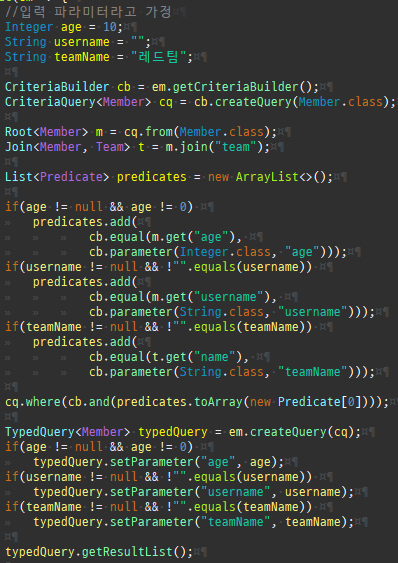
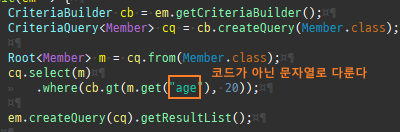
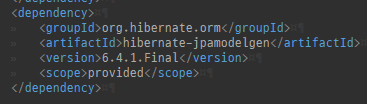
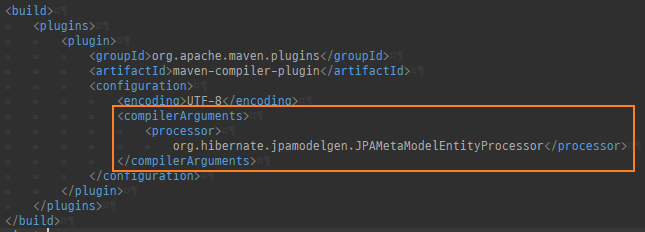
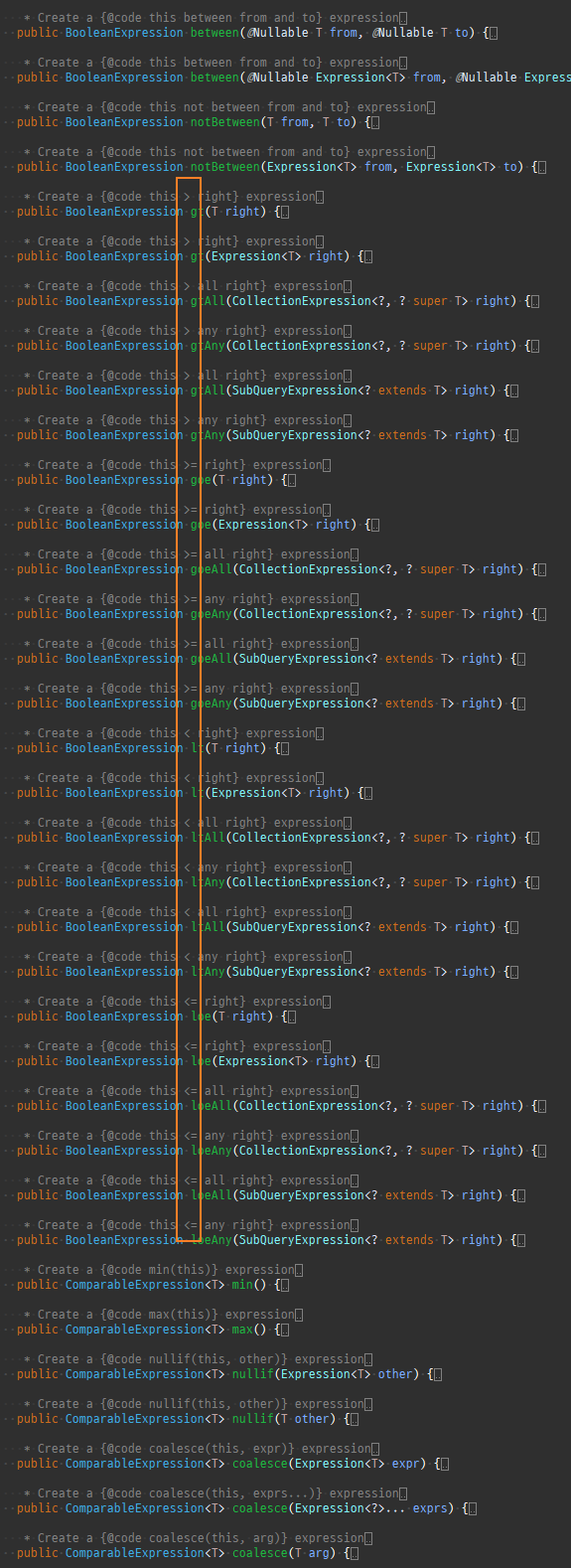

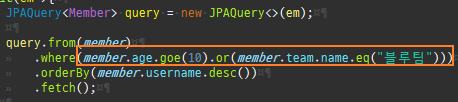
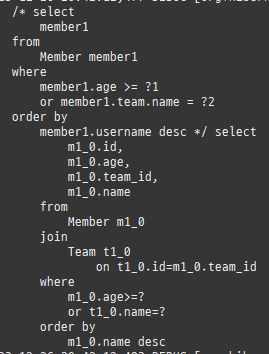
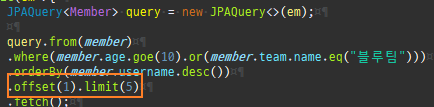


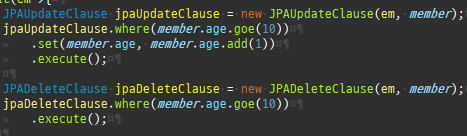
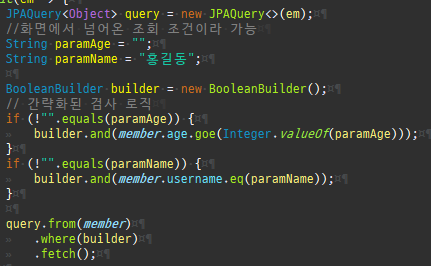
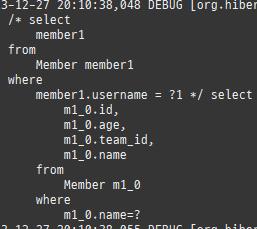
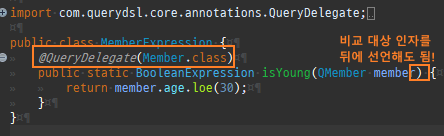



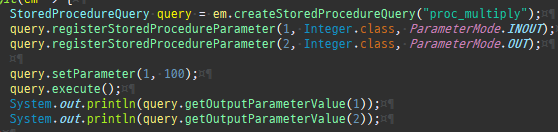
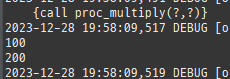
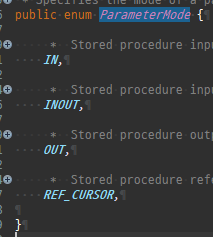
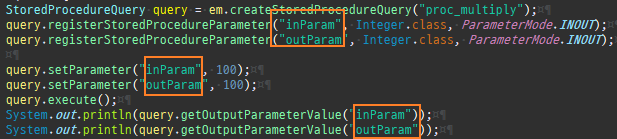





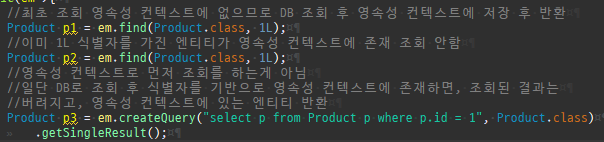
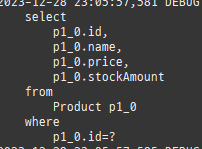
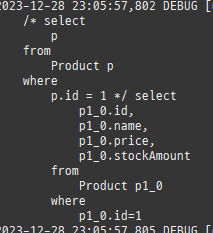





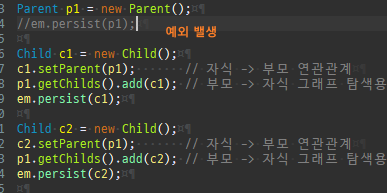
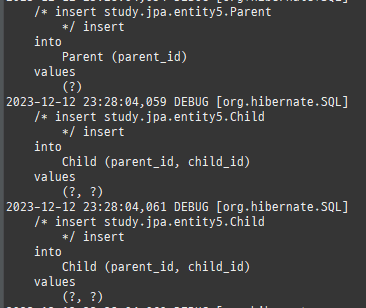
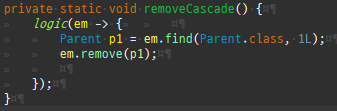

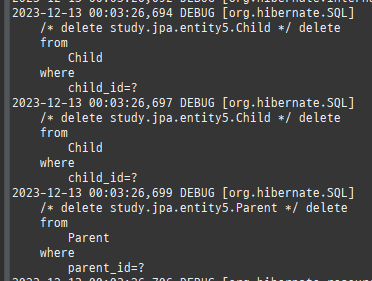











































































































































{kind=link}