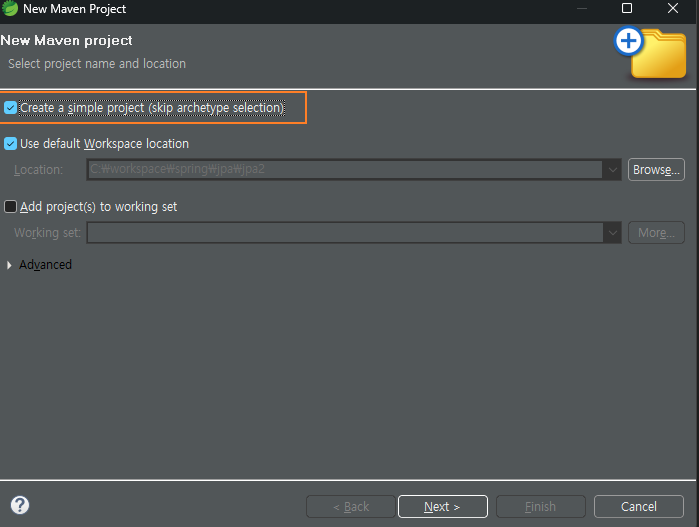
Clean Code(클린 코드) | 로버트 C. 마틴 | 인사이트- 교보ebook
애자일 소프트웨어 장인 정신, 나쁜 코드도 돌아는 간다. 하지만 코드가 깨끗하지 못하면 개발 조직은 기어간다. 매년 지저분한 코드로 수많은 시간과 상당한 자원이 낭비된다. 그래야 할 이유
ebook-product.kyobobook.co.kr
코드
https://github.com/rkwhr0010/clean_code/tree/main/src
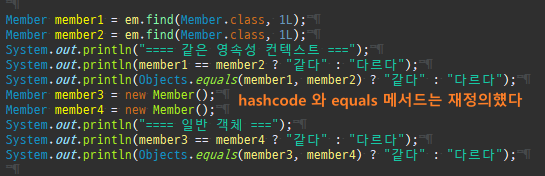
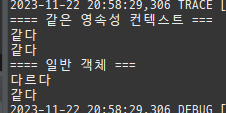
변경 사항은 git history 참고
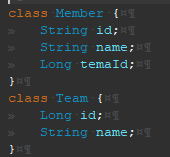
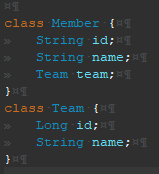
변수를 private으로 정의하는 이유는 남들이 이 변수에 의존하지 않게 만들고 싶기 때문이다.
이렇게 되면, 언제든 개발자가 변수 타입이나 구현을 변경할 수 있다. 의존하는 곳이 없으니까!
그런데 왜 대부분 변수는 private으로 선언하고, getter, setter 는 public으로 당연히 정의할 까?
자료 추상화
| //클래스 구조를 외부로 노출하고 있다. public class Point1 { public double x; public double y; } |
| //구현을 완전히 숨기고 있다. public interface Point2 { double getX(); double getY(); void setCartesian(double x, double y); double getR(); double getTheta(); void setPolar(double r, double theta); } |
Point2 는 자료 구조를 명백하게 표현하고 있다.
뿐만 아니라 메서드로 접근 정책을 강제한다.
x, y 를 한 번에 설정해야 한다. 따로 설정할 방법이 없다.
| /* * 단순히 변수를 private으로 바꾸고 * 그 사이 게터/세터 메서드를 넣는다고,구현이 감춰지지 않는다. * 구현을 감추려면 추상화가 필요하다. */ public class Point3 { //구현을 그대로 노출하는 것이랑 다를바 없다. private double x; private double y; public double getX() { return x; } public void setX(double x) { this.x = x; } public double getY() { return y; } public void setY(double y) { this.y = y; } } |
사용자가 구현을 모른 채 자료의 핵심을 조작할 수 있어야 한다.
| public interface Vehicle1 { double getFuelTankCapacityInGallons(); double getGallonsOfGasoline(); } |
Vehicle1은 "구체적인" 값을 알려준다.
단순히 게터/세터를 설정하는 것과 유사하다.
자료 출처를 명확히 알 수 있다.
| public interface Vehicle2 { double getPercentFuelRemaining(); } |
Vehicle2는 남은 연료 퍼센트를 알려준다.
그 자료를 어디서 읽어와서 퍼센트를 산출하는지 드러나지 않는다.
자료를 세세하게 공개하기보다는 추상적인 개념으로 표현하는 편이 좋다.
아무 생각없이 게터/세터를 추가하는 것으로 추상화는 이뤄지지 않으며, 가장 나쁘다.
자료/객체 비대칭
객체와 자료 구조는 다르다.
앞 예제에서 Point1은 자료구조다.
객체는 추상화 뒤로 자료를 숨긴 채 자료를 다루는 함수만 공개한다.
자료 구조는 자료를 그대로 공개하며 별다른 함수는 제공하지 않는다.
| //절차적 도형 예시 public class Exam01 { //자료구조 public class Point { public double x; public double y; } //자료구조 public class Square { public Point topLeft; public double side; } //자료구조 public class Rectangle { public Point topLeft; public double height; public double width; } //자료구조 public class Circle { public Point center; public double radius; } //동작 방식 정의 public class Geometry { public final double PI = 3.14159265358979323846; public double area(Object shape) throws NoSuchShapeException { if(shape instanceof Square) { Square s = (Square)shape; return s.side * s.side; } else if (shape instanceof Rectangle) { Rectangle s = (Rectangle)shape; return s.height * s.width; } else if (shape instanceof Circle) { Circle s = (Circle)shape; return PI * s.radius * s.radius; } else { throw new NoSuchShapeException(); } } } class NoSuchShapeException extends RuntimeException {} } |
위는 절차적 코드다. 객체 지향으로 설계하지 않았다.
무조건 객체지향으로 설계하는 것이 옳지만은 않다.
예를 들어, 위 코드에서 둘레 길이를 구하는 perimeter() 메서드를 추가한다고 가정하면,
다른 클래스는 전혀 영향을 받지 않는다.
반면에 다른 도형 클래스를 추가하고 싶다면, Geometry 클래스에 속한 메서드를 모두 고쳐야 한다.
| //다형적인 도형 public class Exam02 { interface Shape { double area(); } public class Point { public double x; public double y; } class Square implements Shape { private Point topLeft; private double side; public double area() { return side * side; } } class Rectangle implements Shape { private Point topLeft; private double height; private double width; public double area() { return height * width; } } class Circle implements Shape { private Point center; private double radius; public final double PI = 3.14159265358979323846; public double area() { return PI * radius * radius; } } } |
객제 지향으로 설계한 클래스다.
자료 + 기능 = 객체
여기서는 area()가 다형 메서드고, 동작 방식을 위한 Geometry 클래스는 필요 없다.
그러므로 새로운 도형 클래스를 추가해도 기존 클래스엔 아무런 영향을 미치지 않는다.
반면에 Shape에 새로운 메서드(기능)을 추가 하면, 클래스 전부를 고쳐야 한다.

추가로 상속은 모든 하위 클래스에 영향을 준다. 그래서 상속보단 구성을 사용하는 경우가 많다.
자료구조, 객체지향 장단점
장점
자료구조를 사용하는 절차적인 코드는 기존 자료 구조를 변경하지 않으면서 새 함수를 추가하기 쉽다.
반면, 객체 지향 코드는 기존 함수를 변경하지 않으면서 새 클래스를 추가하기 쉽다.
단점
절차적인 코드는 새로운 자료 구조를 추가하기 어렵다. 그러려면 모든 함수를 고쳐야 한다.
객체 지향 코드는 새로운 함수를 추가하기 어렵다. 그러려면 모든 클래스를 고쳐야 한다.
| 특징\설계 | 절차지향 | 객체지향 |
| 장점 | 함수 추가(기존 자료구조 변경 없음) | 새 클래스 추가(상속, 기존 클래스 변경없음) |
| 단점 | 자료 구조 추가(모든 함수 영향) | 함수 추가(모든 클래스 영향) |
어느 것이 하나가 절대적인 참이 아니다.
잘차지향에서 변경이 쉬운 것은 객체지향에서 어렵다.
그 반대도 똑같다.
디미터 법칙
자신이 조작하는 객체의 속사정을 몰라야 한다는 법칙
객체는 자료를 숨기고, 함수를 공개한다.
객체는 조회 함수(게터)로 내부 구조를 공개하면 안된다.
| class C { List<?> list = new ArrayList<>(); //디미터의 법칙, 다음과 같은 객체의 메서드만 호출해야 한다. List<?> f(List<?> list) { list.add(null);//인수로 넘어온 객체 this.list.add(null);//인스턴스 변수에 저장된 객체 new ArrayList<>().add(null);//메서드 내에서 생성된 객체 //허용된 메서드가 반환하는 메서드는 호출하면 안된다. return new ArrayList<>(); } } |
기차 충돌(trainwreck)
디미터 법칙 어긴 예시
| void exam1() { String outputDir = ctxt.getOptions().getScratchDir().getAbsolutePath(); } |
아래와 같이 나누는 것이 차라리 좋다.
| void exam2() { Options opts = ctxt.getOptions(); File scratchDir = opts.getScratchDir(); String outputDir = scratchDir.getAbsolutePath(); } |
위 코드는 너무 많은 정보를 알고 있어야 한다.
이 메서드가 이 객체를 리턴하고, 이 객체는 또 이 객체를 리턴하는 등…
위 예시가 디미터 법칙을 위반했는지는 객체인지, 자료구조인지에 달렸다.
객체는 내부 구조를 숨겨야 하므로, 어긴 것이 된다.
자료 구조는 당연히 내부 구조를 노출해야 한다. (디미터 법칙 적용 대상이 아님)
더 명백한 자료 구조 표현
| void exam3() { String outputDir = ctxt.options.scratchDir.absolutePath; } |
실제 현업에선 자바빈 규약이 있어, 변수로 접근하지 못하는 경우가 더 많다.
잡종 구조
객체와 자료 구조가 섞인 구조를 말한다.
일부 필드는 비공개 변수를 단순히 공개 게터/세터로 노출, 중요한 기능을 하는 메서드도 존재
구조체 감추기
ctxt, options, scratchDir 이 객체라면, 줄줄이 사탕 형식으로 엮여서는 안 된다.
내부 구조를 감춰야 하기 때문이다.
| void exam1(){ //공개해야하는 메서드가 너무 많다. ctxt.getAbsolutePathOfScratchDirectoryOption(); //getScratchDirectoryOption() 반환하는 값이 자료 구조라고 가정하게 된다.(노출했으니까) ctxt.getScratchDirectoryOption().getAbsolutePath(); } |
ctxt 가 객체라면, 뭔가를 하라고 말해야지 속을 드러내면 안된다. (명령)
결국 절대경로를 리턴하는데, 사용 목적이 없다.
| void exam2() { String classFileName = ""; //코드를 분석해서 메서드 이름을 명시적으로 지었다. //그리고 무언가를 생성하라고 명령했다. (내부 구조 드러냄 없음, 디미터 법칙 준수) BufferedOutputStream bos = ctxt.createScratchFileStream(classFileName); } |
자료 전달 객체(DTO, Data Transfer Object)
보편적인 구조는 public 변수만 존재하고, 메서드는 없는 구조
소켓 통신, DB 등 내외 시스템과 소통 수단으로 유용한 객체다.
가장 일반적인 구조는 자바빈(Bean) 규약을 지키는 빈 구조다.
자바빈 규약 간단한 요약
- 변수 private
- 모든 변수 게터/세터 존재
- 기본 생성자 필수
| public class Address { private String street; private String streetExtra; private String city; private String state; private String zip; public Address(String street, String streetExtra, String city, String state, String zip) { this.street = street; this.streetExtra = streetExtra; this.city = city; this.state = state; this.zip = zip; } public String getStreet() { return street; } public String getStreetExtra() { return streetExtra; } public String getCity() { return city; } public String getState() { return state; } public String getZip() { return zip; } } |
이 구조는 세터는 없다. 즉, 생성자로 생성과 동시에 즉시 사용할 수 있음을 보장한다.
활성 레코드
DTO 의 특수한 형태
DTO + 탐색 함수 제공 (find, save)
활성 레코드는 자료 구조 취급을 해야한다.
탐색 함수가 있다고, 활성 레코드에 비즈니스 로직을 구현하면 안된다.
결론
객체
동작을 공개하고 자료를 숨긴다.
이로 인해 기존 동작을 변경하지 않으면서,
새 객체 타입을 추가하기 쉬워진다.
반면에 기존 객체에 동작을 추가하는 것은 어렵다.
자료구조
동작이 없이 자료만 노출한다.
이로 인해 새 동작을 추가하기 쉬워진다.
반면에 기존 함수에 새 자료 구조를 추가하기는 어렵다.
용도
시스템을 구현할 때 새로운 자료 타입이 계속 늘어날 것 같으면, 객체지향이 적합하다
시스템을 구현할 때 새로운 동작을 계속 추가할 것 같으면, 절차지향이 적합하다.