리팩터링 | 마틴 파울러 | 한빛미디어- 교보ebook
코드 구조를 체계적으로 개선하여 효율적인 리팩터링 구현하기, 20여 년 만에 다시 돌아온 마틴 파울러의 리팩터링 2판 리팩터링 1판은 1999년 출간되었으며, 한국어판은 2002년 한국에 소개되었다
ebook-product.kyobobook.co.kr
리팩터링 적용 방법을 아는 것과 제때 적용할 줄 아는 것은 다르다.
리팩터링을 언제 시작하고 언제 그만할지 판단하는 일은 리팩터링 작동 원리를 아는 것 못지않게 중요하다
다만 이런 기준을 제기할 수는 없다. 프로젝트마다 다 다들 것이기 때문이다.
이 장에선 리팩터링 대상을 찾는 방법을 알려준다.
3.1 기이한 이름
코드는 단순하고 명료한 것이 최선이다.
누가 이름만 보고도 무슨 일을 하고, 어떻게 사용해야 하는지 알 수 있어야 좋은 이름이다.
이름은 IDE로 쉽게 바꿀 수 있으므로 더 좋은 이름이 생각나면 주저하지 말고 바꾸자
이름 바꾸는 것은 이름을 다르게 표현하는 것이 아니다. 적절한 이름이 떠오르지 않는다면 설계에 근본적인 문제가 있을 가능성이 높다.
이름을 잘 정리하면 코드가 간결해져 문맥 파악에 도움된다.
3.2 중복 코드
똑같은 구조 코드가 여러 곳에 반복된다면, 그 코드들의 차이점이 없는지 더 주의깊게 봐야한다.
또한 그 중 하나가 변경사항이 생기면 다른 모든 코드도 살펴봐야한다.
예시
한 클래스에서 두 메서드가 동일한 표현식을 쓴다.
이땐 함수 추출하기로 양 메서드가 추출된 메서드를 호출하게 바꾼다.
두 메서드 코드가 비슷한 경우, 문장 슬라이드하기로 비슷한 부분을 한 곳에 모아 함수 추출하기를 적용할 수 있는지 살펴본다.
같은 부모로부터 파생된 서브 클래스들에 코드 중복이 있다면, 메서드 올리기를 적용해 부모로 옮긴다.
3.3 긴 함수
오랜 기간 잘 활용되는 프로그램들은 짧은 함수로 구성된 경우가 많다.
짧은 함수는 코드가 끝없이 위임하는 방식으로 작성된다.
함수를 짧게 구성할 때, 코드를 이해하고 공유하고 선택하기 쉬워진다.
예전 언어는 호출 비용이 커서 짧은 함수를 피했다.
요즘 언어는 프로세스 안에서의 함수 호출 비용이 거의 없다.
짧은 함수로 구성된 코드를 이해하기 쉽게 만드려면 좋은 이름을 지어야 한다.
좋은 이름을 가진 함수는 본문을 볼 필요가 없다.
이러기 위해서 적극적으로 함수를 쪼개야 한다.
주석을 달아야 할 코드는 함수로 만든다.
원래 코드보다 길어지더라도 함수로 만든다.
함수 이름을 지을 땐, 동작방식이 아닌 이 함수가 무엇을 하는지에 대한 '의도'를 표현해야한다.
함수를 짧게 만드는 작업은 거의 합수 추출하기로 한다.
매개변수와 임시 변수가 많으면 함수 추출하기 힘들다. 이런 상황에서 함수 추출 시 똑같이 추출된 함수로 매개변수가 많아진다.
임시 변수를 질의 함수로 바꾸기로 임시 변수 수를 줄일 수 있다.
매개변수 객체 만들기와 객체 통째로 넘기기로 매개변수 수를 줄일 수 있다.
추출할 코드를 찾는 방법으로 주석 살펴보기가 있다. 보통 주석은 이해하기 난해한 곳에 붙어있기 때문이다.
조건문과 반복문도 추출 대상 후보다.
조건문은 조건문 분해하기를 적용한다.
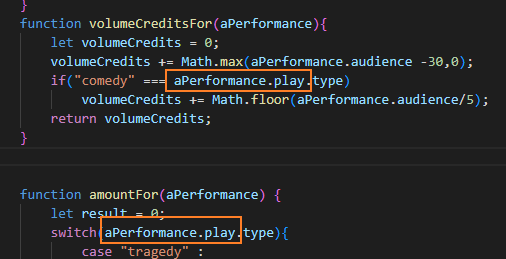
switch문은 case 마다 함수 추출하기를 적용한다.
같은 조건을 기준으로 나뉘는 switch문은 조건부 로직을 다형성으로 바꾸기를 적용한다.
반복문도 그 안 코드를 추출해 함수를 만든다. 이때 함수에 적합한 이름이 떠오르지 않는다면, 그 함수는 두 가지 이상 작업이 섞여 있을 가능성이 있다. 이땐 반복문 쪼개기를 적용해 작업을 분리한다.
3.4 긴 매개변수 목록
매개변수 목록이 길어지면 그 자체로 이해하기 어려워진다.
다른 매개변수에서 값을 얻어올 수 있는 매개변수는 매개변수를 질의 함수로 바꾸기로 제거할 수 있다.
사용 중인 데이터 구조에서 값들을 뽑아 각각 별개 매개변수로 전달하는 코드는 객체 통째로 넘기기를 적용해서 원본 데이터 구조를 그대로 넘긴다.
항상 함께 전달되는 매개변수들은 매개변수 객체 만들기로 하나로 묶어버린다.
함수 동작방식을 정하는 플래그 매개변수는 플래그 인수 제거하기로 없앤다.
클래스는 매개변수 목록을 줄이는 데 효과적인 수단이다.
여러 함수 간 특정 매개변수들의 값을 공통으로 사용할 때 여러 함수를 클래스로 묶기를 적용해 공통 값들을 클래스의 필드로 정의한다.
3.5 전역 데이터
가장 악취가 지독한 축에 속한다.
전역 데이터의 문제는 코드 베이스 어디에서든 건드릴 수 있기 때문에 누가 값을 바꿨는지 찾아낼 메커니즘이 없다.
전역 데이터의 대표적인 형태는 전역 변수지만 클래스 변수와 싱글톤도 같은 문제를 공유한다.
이를 방지하기 위해 변수 캡슐화하기를 적용한다.
데이터를 함수로 감싸는 것만으로도 데이터 수정하는 부분을 쉽게 찾을 수 있고, 접근 제한을 할 수 있다. 나아가 접근자 함수들을 클래스나 모듈에 넣고, 그 안에서만 사용할 수 있도록 접근 범위를 최소로 제한할 수 있다.
3.6 가변 데이터
코드의 다른 곳에서 다른 값을 기대한다는 사실을 모르고 수정해버리면 오작동하게 된다.
이 문제가 드문 조건에서만 발생한다면 원인은 더 찾기 힘들다.
이런 문제로 함수형 프로그래밍에서는 데이터는 변하지 않고, 데이터 변경 시 복사본을 사용하여 반환한다.
데이터 수정에 따른 위험을 줄이는 방법
변수 캡슐화하기를 적용해 함수를 통해서만 값을 수정하도록 해 감시
하나의 변수 용도가 다른 값들을 저장하느라 값을 갱신한다면 변수 쪼개기를 이용하여 용도별로 독립 변수에 저장하여 값 갱신 발생 여지를 없앤다. 그리고 갱신로직은 다른 코드와 떨어트린다.
API를 만들 때는 질의 함수와 변경 함수 분리하기를 적용해 필요한 경우에만 사이드이펙트가 있는 함수를 호출하도록 한다.
가능한 세터 제거하기
값을 다른 곳에서 설정할 수 있는 가변 데이터는 특히 위험하다. 이 경우 파생 변수를 질의 함수로 바꾸기를 적용한다.
유효범위가 좁다면 가변 데이터라도 문제를 잘 일으키지 않는다. 하지만 나중에 유효범위가 넓어질 수 있기 때문에 여러 함수를 클래스로 묶기나 여러 함수를 변환 함수로 묶기를 활용해 변수를 갱신하는 코드들의 유효범위를 제한한다.
구조체처럼 내부 필드에 데이터를 담고 있는 변수는 참조를 값으로 바꾸기를 적용하여, 내부 필드를 직접 수정하지 말고 구조체를 통째로 교체하는 것이 좋다.
3.7 뒤엉킨 변경
개발자는 코드를 수정할 때 시스템에서 고쳐야 할 딱 한 군데를 찾아서 그 부분만을 수정하길 바란다. 이것이 불가능하다면 뒤엉킨 변경과 산탄총 수술 중 하나이다.
뒤엉킨 변경은 단일 책임 원칙이 제대로 지켜지지 않을 때 나타난다.
하나의 모듈이 서로 다른 이유들로 인해 여러 가지 방식으로 변경되는 일이 많을 때 발생한다.
예시로 DB추가 될 때 함수 세 개를 바꿔야 한다면 뒤엉킨 변경이 발생한 것이다.
순차적으로 실행되는게 자연스러운 맥락이라면, 다음 맥락에 필요한 데이터를 특정한 데이터 구조에 담아 전달하게 하는 식으로 단계 분리한다.
전체 처리 과정 곳곳에서 각기 다른 맥락의 함수를 호출하는 빈도가 높다면, 각 맥락에 해당하는 적당한 모듈들을 만들어서 관련 함수들을 모은다.
3.8 산탄총 수술
뒤엉킨 변경과 비슷하면서도 정반대
코드가 변경할 때마다 자잘하게 수정해야 하는 클래스가 많을 때,
변경할 부분이 퍼져 있다면, 수정을 다 못할 확률이 증가한다.
이럴 땐 변경 대상들을 함수 옮기기와 필드 옮기기로 모두 한 모듈에 묶어두면 좋다.
비슷한 데이터를 다루는 함수가 많으면 여러 함수를 클래스로 묶기를 적용한다
데이터 구조를 변환하거나 보강하는 함수들에는 여러 함수를 변환 함수로 묶기를 적용한다.
어설프게 분리된 로직을 함수 인라인하기나 클래스 인라인하기 같은 인라인 리팩터링으로 하나로 함치는 것도 하나의 방법이다.
메서드나 클래스가 비대해지지만, 인라인류는 나중에 추출하기 리팩터링이 용이해진다.
3.9 기능 편애
프로그램 모듈화할 땐 코드를 여러 영역으로 나눈 뒤 같은 영역 내에서 상호작용은 늘리고, 영역 사이 상호작용은 줄이는 데 주력한다.
기능편애는 어떤 함수가 자기가 속한 모듈의 함수나 데이터보다 다른 모듈의 함수나 데이터와 상호작용 할 일이 더 많을 때 풍기는 냄새다.
대게 함수 옮기기나 함수 추출하기로 옮기면 된다.
함수가 사용하는 모듈이 다양해 어디로 옮길지 명확하지 않을 때는 가장 많은 데이터를 포함한 모듈로 옮긴다. 그리고 함수 추출하기로 함수를 여러 조각으로 나눈 후 적합한 모듈로 옮긴다.
전략 패턴과 방문자 패턴은 뒤엉킨 변경 냄새를 없앨 때 활용하는 패턴이다.
함께 변경할 대상을 한데 모은다.
3.10 데이터 뭉치
데이터 항목이 여러 곳에서 함상 함께 뭉쳐 다니는 것을 말한다.
이 경우 클래스 추출하기로 하나의 객체로 묶는다. 그리고 매개변수 객체 만들기나 객체 통째로 넘기기로 매개변수 수를 줄인다.
매개변수로 넘긴 클래스가 그 함수 내에서 데이터를 전부 사용하지 않아도 된다. 중요한 것은 전보다 함수 선언부가 깔끔해진다는 것
데이터 뭉치인지 판별하는 방법은 데이터 뭉치 중 하나만 지워봤을 때 나머지 데이터만으로는 의미가 없다면, 데이터 뭉치이다.
3.11 기본형 집착
자신에게 주어진 문제에 딱 맞는 기초 타입을 직접 정의하기를 꺼리는 것을 말한다.
주로 문자열을 다룰 때 흔히 나타난다.
전화번호를 예를 들면, 단순히 문자열로만 표현하기엔 부족하다. 사용자에게 보여줄 때 일관된 형식으로 출력해주는 기능이라도 있어야한다.
기본형을 객체로 바꾸기를 적용해 의미있는 자료형으로 변경하는게 좋다.
3.12 반복되는 switch문
중복된 switch문이 문제가 되는 이유는 조건절을 하나 추가할 때마다 다른 switch문들도 모두 찾아서 함께 수정해야 하기 때문이다. 이럴 때 다형성은 반복된 switch문의 문제를 효과적으로 해결해준다.
3.13 반복문
과거 언어들은 반복문에 대안을 제시하지 못했다. 현재 언어들은 일급 함수를 지원하는 경우가 많아 반복문을 파이프라인으로 바꾸기를 적용해 반복문을 제거할 수 있다.
3.14 성의없는 요소
프로그래밍 언어가 제공하는 함수, 클래스, 인터페이스 등 코드 구조를 잡는데 활용하는 것이 요소다.
성의없는 요쇼로는 본문 코드를 그대로 쓰는 것과 다름없는 함수, 실질적인 메서드는 하나뿐인 클래스 등이 있다.
함수 인라인하기나 클래스 인라인하기, 상속을 사용했다면 계층 합치기로 제거한다.
3.15 추측성 일반화
나중에 필요할 거라는 생각으로 만든 코드를 말한다. 당장은 필요 없는 후킹(hooking)포인트와 특이 케이스 처리 로직을 작성해둔 코드에서 나타만다.
하는 일이 거의 없는 추상 클래스는 계층 합치기로 제거
쓸데없이 위임하는 코드는 함수 인라인하기나 클래스 인라인하기로 제거
본문에서 사용되지 않는 매개변수는 함수 선언 바꾸기로 제거
추측성 일반화 코드는 테스트 코드에서만 사용하는 함수나 클래스에서 흔히 볼 수 있다.
3.16 임시 필드
임시 필드를 갖도록 작성하면 코드를 이해하기 어렵다. 사용자는 쓰이지 않는 것처럼 보이는 필드가 존재하는 이유를 파악하느라 골치 아프다.
이런 필드들을 발견하면 클래스 추출하기로 옮긴다. 그리고 함수 옮기기로 임시 필드들과 관련된 코드를 새 클래스로 옮긴다.
3.17 메시지 체인
클라이언트가 한 객체를 통해 다른 객체를 얻은 뒤 방금 얻은 객체에 또 다른 객체를 요청하는 식으로, 다른 객체를 요청하는 작업이 연쇄적으로 이어지는 코드를 말한다.
이럴 경우 중간 단계를 수정하면 클라이언트 코드도 수정해야 한다.
이 문제는 위임 숨기기로 해결할 수 있다.
이 래픽터링은 여러 지점에 사용할 수 있지만, 이러면 모두 중개자가 돼버린다.
3.18 중개자
객체의 대표적인 기능 하나로, 외부로부터 세부사항을 숨겨주는 캡슐화가 있다.
캡슐화하는 과정에서 위임이 자주 활용된다.
위임이 지나치면 문제가 된다. 클래스 메서드 대부분이 다른 클래스에 구현을 위임하고 있다면, 중개자 제거하기를 통해 실제로 일하는 객체와 직접 소통하도록 만든다.
3.19 내부자 거래
모듈 사이의 거래가 많으면 결합도가 높아진다고 한다. 따라서 그 빈도를 낮추는 것이 좋다.
데이터를 주고 받는 모듈들이 있다면 함수 옮기기와 필드 옮기기로 떼어놓아서 사적으로 처리하는 부분을 줄인다.
여러 모듈이 같은 관심사를 공유한다면 공통 부분을 정식으로 처리하는 제3의 모듈을 새로 만들거나 위임 숨기기를 이용해 다른 모듈이 중간자 역할을 하게 한다.
3.20 거대한 클래스
한 클래스가 너무 많은 일을 하면 필드 수가 늘어나고 클래스에 필드가 많으면 중복 코드가 생기기 쉽다.
클래스 추출하기로 유사한 필드들 일부를 따로 묶는다.
일반적으로 접두나 접미가 같은 필드들이 좋은 후보군이 된다.
분리할 컴포넌트를 원래 클래스의 상속관계로 만들고 싶다면 슈퍼클래스 추출하기나 타입 코드를 서브클래스로 바꾸기를 적용한다.
코드량이 많은 클래스도 중복 코드와 혼동을 을으킬 여지가 크다. 이럴 땐 클래스 내부에서 중복을 제거한다.
클라이언트들이 거대 클래스를 이용하는지 패턴을 파악하여 그 클래스를 쪼갤지 단서를 얻을 수도 있다. 클라이언트들이 거대 클래스의 특정 기능 그룹만 주로 사용하면, 기능 그룹을 여러 클래스로 분리한다.
3.21 서로 다른 인터페이스의 대안 클래스들
클래스를 사용할 때 장점은 필요에 따라 다른 클래스로 교체할 수 있다는 점이다
교체하려면 인터페이스가 같아야 한다. 따라서 함수 선언 바꾸기로 메서드 시그니처를 일치시킨다. 이것만으로 부족하면. 함수 옮기기를 이용해 인터페이스가 같아질 때까지 필요한 동작들을 클래스 안으로 넣는다. 이과정에서 클래스들 사이 중복 코드가 생기면 슈퍼클래스 추출하기를 사용한다.
3.22 데이터 클래스
데이터 클래스는 데이터 필드와 그에 따른 게터/세터만 있는 클래스
단순히 데이터 저장 용도로만 쓰인다. 이 때문에 함부로 다를 때가 많다.
public 필드가 있다면 레코드 캡슐화하기로 숨긴다. 변경하면 안되는 필드는 세터를 제거한다.
게터나 세터를 사용하는 메서드를 찾아서 함수 옮기기로 데이터 클래스로 옮길 수 있는지 확인한다.
메서드를 옮기기 힘들다면 함수 추출하기로 옮길 수 있는 부분만 별도 메서드로 뽑아낸다.
3.23 상속 포기
서브클래스에서 부모로부터 상속받기 싫은 경우
같은 계층에 서브클래스를 하나 새로 만들고, 메서드 내리기와 필드 내리기를 활용해서 물려받지 않을 부모 코드를 새로 만든 서브클래스로 넘긴다. 그러면 부모 클래스에는 공통부분만 남는다
현재는 이 방식을 권하지 않는다. 일부 동작을 재활용하기 위해 상속을 사용하기도 하는데, 실무에선 유용하기 때문이다. 냄새가 나긴해도 심한 정도가 아니다.
상속 포기 냄새는 서브클래스가 부모의 동작은 필요로 하지만 인터페이스는 따르고 싶지 않을 때 심하게 난다. 인터페이스를 따르지 않을 거면, 아예 상속 메커니즘에서 빼야한다.
3.24 주석
주석이 장황할 수록 코드를 잘못 작성했기 때문인 경우가 많다.
주석을 남겨야할 것 같으면 먼저 함수를 리팩터링해본다. 그래도 필요하다 싶으면 남긴다.
'IT책, 강의 > 리팩터링' 카테고리의 다른 글
| 06 - 기본적인 리팩터링 - 함수 추출하기 (0) | 2023.07.14 |
|---|---|
| 04 - 테스트 구축하기 (1) | 2023.07.12 |
| 02 - 리팩터링 원칙 - 02 (0) | 2023.07.08 |
| 02 - 리팩터링 원칙 - 01 (0) | 2023.07.06 |
| 01 - 리팩터링: 첫 번째 예시 - 02 (0) | 2023.07.04 |