Clean Code(클린 코드) | 로버트 C. 마틴 | 인사이트- 교보ebook
애자일 소프트웨어 장인 정신, 나쁜 코드도 돌아는 간다. 하지만 코드가 깨끗하지 못하면 개발 조직은 기어간다. 매년 지저분한 코드로 수많은 시간과 상당한 자원이 낭비된다. 그래야 할 이유
ebook-product.kyobobook.co.kr
코드
https://github.com/rkwhr0010/clean_code/tree/main/src
변경 사항은 git history 참고
오래된 주석은 거짓 정보를 퍼트린다.
거짓된 주석은 없는 것보다 나쁘다.
주석은 순수하게 선하지 않다. 필요악이다.
코드 자체가 표현력이 풍부하다면, 필요하지 않다.
따라서 주석을 단다는 것은 자신의 표현력이 부족하는 것이다.
좋은 주석이라도 시간이 지나면서, 관리되지 않아 나쁜 주석이 된다. 현실적으로 주석은 잘 관리 되지 않는다.
코드만이 거짓을 말하지 않는다. 최대한 주석이 없는 방향으로 개발해야 한다.
주석은 나쁜 코드를 보완하지 못한다
주석은 코드 품질이 나쁠 때 단다. 따라서 주석이 보이면, 코드를 정리해야 한다
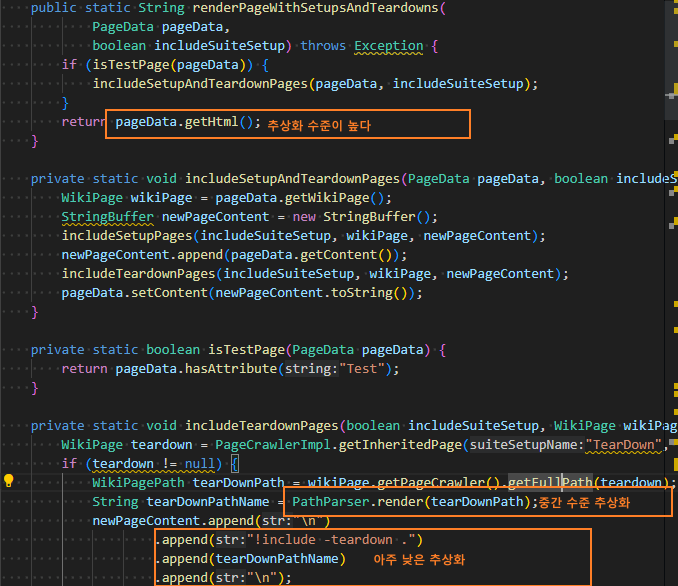
코드로 의도를 표현하라!
| //어느것이 더 좋은지 비교 void example() { //직원에게 복지 혜택을 받을 자격이 있는지 검사 if((employee.flags & HOURLY_FLAG) && employee.age > 65) { /* ~~~~ */ } if(employee.isEligibleForFullBenefits()) { /* ~~~~ */ } |
좋은 주석
필수 정보는 주석을 달 수 밖에 없다.
법적인 주석
코드 상단에 카피라이트에 해당된다.

정보를 제공하는 주석
코드로 표현이 도저히 힘든 정규식 같은게 좋은 예다.
| //kk:mm:ss EEE, MMM dd, yyyy 형식 Pattern timeMatcher = Pattern.compile( "\\d*:\\d*:\\d* \\w*, \\w* \\d*, \\d*"); |
이 마저도 시간과 날짜를 변환해주는 클래스를 별도로 만들어 옮기면, 주석이 필요하지 않다.
의도를 설명하는 주석
| public int compareTo(Object o) { if(o instanceof WikiPagePath) { WikiPagePath p = (WikiPagePath) o; String compressedName = StringUtil.join(names, ""); String compressedArgumentName = StringUtil.join(p.names, ""); return compressedName.compareTo(compressedArgumentName); } return 1; //오른쪽 유형이므로 정렬 순위가 더 높다. } |
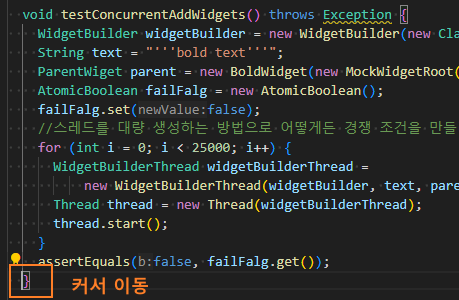
| void testConcurrentAddWidgets() throws Exception { WidgetBuilder widgetBuilder = new WidgetBuilder(new Class[]{BoldWidget.class}); String text = "'''bold text'''"; ParentWiget parent = new BoldWidget(new MockWidgetRoot(), "'''bold test'''"); AtomicBoolean failFalg = new AtomicBoolean(); failFalg.set(false); //스레드를 대량 생성하는 방법으로 어떻게든 경쟁 조건을 만들려 시도한다. for (int i = 0; i < 25000; i++) { WidgetBuilderThread widgetBuilderThread = new WidgetBuilderThread(widgetBuilder, text, parent, failFalg); Thread thread = new Thread(widgetBuilderThread); thread.start(); } assertEquals(false, failFalg.get()); } |
의미를 명료하게 밝히는 주석
| void testCompareTo() throws Exception { WikiPagePath a = PathParser.parse("PageA"); WikiPagePath ab = PathParser.parse("PageA.PageB"); WikiPagePath b = PathParser.parse("PageB"); WikiPagePath aa = PathParser.parse("PageA.PageA"); WikiPagePath bb = PathParser.parse("PageB.PageB"); WikiPagePath ba = PathParser.parse("PageB.PageA"); //assertTrue 가 라이브러리를 사용한 것이라고 가정 assertTrue(a.compareTo(a) == 0); // a == a assertTrue(a.compareTo(b) != 0); // a != b assertTrue(a.compareTo(b) == -1);// a < b } |
모호한 인수나 반환값을 의미를 좋게 표현하려고 바꾸고 싶지만,
라이브러리를 사용하는 경우 변경이 불가하다. 이 경우는 주석이 유용하다.
물론 주석을 완전히 신뢰할 수 없다는 문제가 남아있다.
이 처럼 주석은 다른 방법으로 표현할 방법이 없는 지 고민 후 달아야 한다.
결과를 경고하는 주석
특정 테스트 케이스가 수행 시간이 오래걸린다면, 이를 위한 경고는 괜찮다.
요즘은 @Ignore 어노테이션 같은 것으로 그 안에 사유를 적어 주석보다 더 명시적으로 사용한다.
또는 해당 코드가 스레드 세이프하지 않을 때 경고를 남기기도 한다
TODO 주석
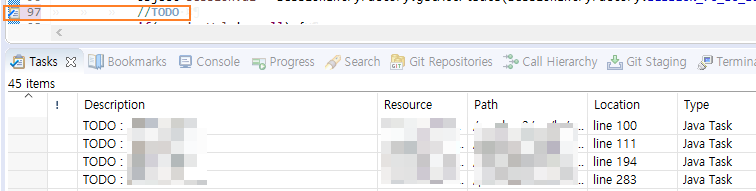
요즘 IDE는 TODO를 인식 해서 보여주는 기능이 있다.
보통은 현재 구현이 어려운 코드를 TODO 주석으로 남길 것이다.
따라서 이를 주기적으로 체크해 줄여가야 한다.
중요성을 강조하는 주석
얼핏 봤을 때 대수롭지 않게 넘길 만한 코드에 중요한 사실을 경고할 때
| //trim() 중요하다. 시작에 공백이 들어가 있으면, 다른 문자열로 인식된다. String listItemContent = match.group(3).trim(); new ListItemWidget(this, listItemContent, this.level + 1); return buildList(text.substring(match.end())); |
공개 API에서 Javadocs
Javadocs를 만들기로 했으면, 정말 잘 만들어야 한다.
잘 만든 공개 API Javadocs는 훌륭하다.
나쁜 주석
대부분의 주석이 해당된다.
주절거리는 주석
무언가를 설명하려고 주석을 달 생각이면, 최대한 의미있게 자세히 서술해야 한다.
설명이 미흡하면, 결국 그 주석의 의미는 희미해지고, 코드를 뒤지며 로직을 확인해야 한다.
같은 이야기를 중복하는 주석
변수나 함수 이름만으로도 충분한데, 의미 없이 중복된 내용을 주석으로 작성한 것을 말한다.
| /* * this.closed 가 true 일 때 반환되는 메서드 * 타임아웃에 도달하면 예외를 던진다. */ synchronized void waitForClose(final long timeoutMillis) throws Exception { if(!closed) { wait(timeoutMillis); if(!closed) { throw new Exception("MockResponseSender Could not be closed"); } } } |
| /* 로그를 찍기 위한 로거 */ Logger logger; |
오해할 여지가 있는 주석
의무적으로 다는 주석
자바독 예시
| /** * @param title CD 제목 * @param author CD 저자 * @param tracks CD 트랙수 * @param durationInMinutes CD 분 길이 */ public void addCd(String title, String author, int tracks, int durationInMinutes) { } |
오히려 가독성만 저해한다.
이력을 기록하는 주석
Git 과 같은 형상관리 프로그램이 이력을 저장하고 있다.
이제 필요없다.
있으나 마나 한 주석
이런 주석을 자주 접하면, 개발자는 주석을 무시하게 된다.
그러면 정말 중요한 주석인 경우 안 읽게 된다.
위치는 표시하는 주석
// 여기 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
이런 류 주석이다. 한 시적으로 혼자만 가끔 사용할 순 있어도 커밋 시점엔 제거돼야 한다.
닫는 괄호에 다는 주석
예전에 IDE가 없던 시절에는 함수가 길어지면, 찾기 힘들 었다
현재는 IDE가 닫은 괄호를 눈에 띄게 표시해주며, 특히 여는 괄호에서 닫는 괄호로 이동 기능도 제공한다.
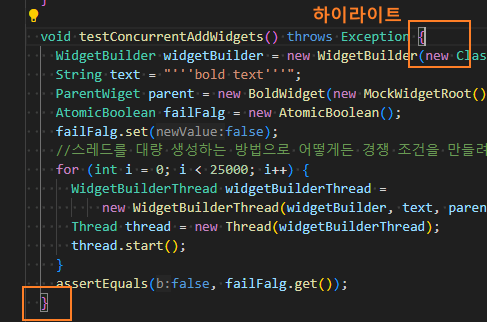
Vscode는 Ctrl + Shift + P 가 괄호 간 이동 단축키다.
공로를 돌리거나 저자를 표시하는 주석
형상 관리 프로그램이 관리한다.
주석으로 처리한 코드
언젠가 필요할 까봐 주석으로 남기는 코드가 있다.
이 역시 형상 관리 프로그램으로 과거 코드를 언제든지 접근할 수 있으므로 제거한다.
HTML주석
Javadocs 를 작성할 때 주석에 HTML 태그를 사용한다. 이렇게 되면 javadocs를 만들지 않는 이상 주석만 보고 파악하기 힘들다.
현재 IDE는 팝업 같은 형식으로 보기 편하게 지원해서 의미는 없는 듯하다.
전역 정보
주석을 단다면 주변 코드 정보만 달아야 한다. 전역 시스템 정보를 달면 안된다.
조금이라도 코드에 변경이 생기면, 전역 주석을 항상 최신화 할 수 있는가
너무 많은 정보
예를 들어 JWT 라이브러리를 사용하는데 라이브러리 주석에 JWT 동작방식이 써 있다고 생각하면 이해가 쉽다.
모호한 관계
코드와 이를 설명하는 주석의 관계가 명확하지 않는 경우를 말한다.
비공개 코드에서 Javadocs
공개 API에선 의미가 있지만, 비공개 코드에선 의미가 없다. 오히려 코드를 읽기 힘들게 한다.
예제
리팩터링 전
| package chap04.ex07; /** * 이 클래스는 사용자가 지정한 최대 값까지 소수를 생성한다. * 사용된 알고리즘은 에라스토테네스의 체다. * * 에라스토테네스 소개 [의미없는 주석] * ~~~~~~~~~~~~~~~~~~ * * 알고리즘 설명 * ~~~~~~~~~~~~~~~~~~ * * @author 누군가 * @version 2023.09.01 */ public class GeneratePrimes { /** [의미없는 주석] * @param maxValue는 소수를 찾아낼 최대 값 */ //지나지게 거대한 메서드 public static int[] generatePrimes(int maxValue) { if (maxValue > 2) { //유일하게 유효한 경우 [의미없는 주석] //선언 int s = maxValue + 1; boolean[] f = new boolean[s]; int i; //배열을 참으로 초기화 [의미없는 주석] 메서드로 뺄 것(메서드 이름을 명시적으로) for(i = 0; i < s; i++) { f[i] = true; } //소수가 아닌 알려진 숫자를 제거 [의미없는 주석] f[0] = f[1] = false; //체 [의미없는 주석] [의미없는 주석] 메서드로 뺄 것(메서드 이름을 명시적으로) int j; for (i = 2; i < Math.sqrt(s) + 1; i++) { if (f[i]) { for (j = 2 * i; j < s; j += i) { f[j] = false; //배수는 소수가 아니다. } } } //소수 개수는? [의미없는 주석] 메서드로 뺄 것(메서드 이름을 명시적으로) int count = 0; for (i = 0; i < s; i++) { if (f[i]) { count++; // 카운트 증가 } } int[] primes = new int[count]; // 소수를 결과 배열로 이동한다. [의미없는 주석] 메서드로 뺄 것(메서드 이름을 명시적으로) for (i = 0, j = 0; i < s; i++) { if (f[i]) { primes[j++] = i; } } return primes; } else { // maxValue < 2 [의미없는 주석] return new int[0]; //입력이 잘못되면 비어 있는 배열을 반환하다. [의미없는 주석] } } } |
리팩터링 후
| package chap04.ex07; /** * 이 클래스는 사용자가 지정한 최대 값까지 소수를 구한다. * 알고리즘은 에라스토테네스의 체다. * 2에서 시작하는 정수 배열을 대상으로 작업한다. * 처음으로 남아 있는 정수를 찾아 배수를 모두 제거한다. * 배열에 더 이상 배수가 없을 때까지 반복한다. */ public class PrimeGenerator { private static boolean[] crossedOut; private static int[] result; public static int[] generatePrimes(int maxValue) { if (maxValue < 2) { return new int[0]; } else { uncrossIntegersUpTo(maxValue); crossOutMultiples(); putUncrossedIntegersIntoResult(); return result; } } private static void uncrossIntegersUpTo(int maxValue) { crossedOut = new boolean[maxValue + 1]; for (int i = 2; i < crossedOut.length; i++) { crossedOut[i] = false; } } private static void crossOutMultiples() { int limit = determineIterationLimit(); for (int i = 2; i <= limit; i++) { if (notCrossed(i)) { crossOutMultiplesOf(i); } } } private static int determineIterationLimit() { /* * 배열에 있는 모든 배수는 배열의 제곱근보다 작은 소수의 인수다. * 따라서 이 제곱근보다 더 큰 숫자의 배수는 제거할 필요가 없다. */ double iterationLimit = Math.sqrt(crossedOut.length); return (int) iterationLimit; } private static void crossOutMultiplesOf(int i) { for (int multiple = 2 * i; multiple < crossedOut.length; multiple += i) { crossedOut[multiple] = true; } } private static boolean notCrossed(int i) { return crossedOut[i] == false; } private static void putUncrossedIntegersIntoResult() { result = new int[numberOfUncrossedIntegers()]; for(int j = 0, i = 2; i < crossedOut.length; i++) { if (notCrossed(i)) { result[j++] = i; } } } private static int numberOfUncrossedIntegers() { int count = 0; for (int i =2; i < crossedOut.length; i++) { if (notCrossed(i)) { count++; } } return count; } } |
'IT책, 강의 > 클린코드(Clean Code)' 카테고리의 다른 글
| 6장 객체와 자료 구조 (1) | 2023.12.18 |
|---|---|
| 5장 형식 맞추기 (0) | 2023.12.11 |
| 3장 함수 (1) | 2023.11.27 |
| 2장 의미 있는 이름 (1) | 2023.11.20 |
| 1장 깨끗한 코드 (0) | 2023.11.13 |