SELECT DATA
, TRANSLATE (DATA, ' 1234567890', ' ') AS "숫자만제거"
, TRANSLATE (DATA, '1234567890'||DATA, '1234567890') AS "숫자만남기기"
, TRANSLATE (LOWER(DATA), ' abcdefghijklmnopqrstuvwxyz' , ' ' ) AS "문자만제거"
, TRANSLATE (LOWER(DATA), 'abcdefghijklmnopqrstuvwxyz'||DATA , 'abcdefghijklmnopqrstuvwxyz' ) AS "문자만남기기"
FROM (SELECT EMPNO||ENAME||HIREDATE AS DATA
FROM EMP )
DATA
숫자만제거
숫자만남기기
문자만제거
문자만남기기
7698BLAKE81/05/01
BLAKE//
7698810501
769881/05/01
blake
7782CLARK81/06/09
CLARK//
7782810609
778281/06/09
clark
7566JONES81/04/02
JONES//
7566810402
756681/04/02
jones
7902FORD81/12/03
FORD//
7902811203
790281/12/03
ford
7369SMITH80/12/17
SMITH//
7369801217
736980/12/17
smith
7499ALLEN81/02/20
ALLEN//
7499810220
749981/02/20
allen
7521WARD81/02/22
WARD//
7521810222
752181/02/22
ward
7654MARTIN81/09/28
MARTIN//
7654810928
765481/09/28
martin
7844TURNER81/09/08
TURNER//
7844810908
784481/09/08
turner
7900JAMES81/12/03
JAMES//
7900811203
790081/12/03
james
7934MILLER82/01/23
MILLER//
7934820123
793482/01/23
miller
7876ADAMS87/05/23
ADAMS//
7876870523
787687/05/23
adams
7788SCOTT87/04/19
SCOTT//
7788870419
778887/04/19
scott
1111YODA81/11/17
YODA//
1111811117
111181/11/17
yoda
7839KING81/11/17
KING//
7839811117
783981/11/17
king
TRANSLATE 만 이해하면 문자열 다루는 함수는 거의 다 이해한 것이나 다름이 없다.
TRANSLATE( 데이터, 검색문자 , 치환문자)
문제
SELECT TRANSLATE ('abcde', '1234567890', ' ') FROM DUAL
정답은?
'abcde' 그대로 출력된다. '1234567890' 로 검색해서 일치하는 것이 없기 때문이다.
문제
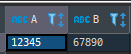
SELECT TRANSLATE ('12345', '1234567890', '12345') A
, TRANSLATE ('12345', '1234567890', '67890') B
FROM dual
A,B 결과는?
여기서 중요한 것은 A도 똑같지만 특히 B가 왜 '67890'이라는 결과가 나왔는지다
'1234567890' 에서 '67890' 이 있으니까 '67890' 나왔다고 생각했다면 틀렸다.
SELECT TRANSLATE ('12345', '1234567890', '12345') A
, TRANSLATE ('12345', '1234567890', '67890') B
, TRANSLATE ('12345', '1234567890', '0000067890') C
FROM dual
C가 어떤 결과가 나올 것 같은가?
답은 '00000' 이다.
즉, 앞서 A 도 '12345' 가 '12345' 가 그대로 출력된게 아니라 치환되어 '12345'가 된것으로 값이 잘 맞아 떨어져 그대로 출력하게 된 것 처럼 보인 것이다.
즉, A, B 다 치환된 결과이다.
'1234567890' 검색문자가 어떻게 치환되는지 알아보자
문제
SELECT TRANSLATE ('54321', '1234567890', '12345') A
, TRANSLATE ('54321', '1234567890', '67890') B
, TRANSLATE ('54321', '1234567890', '0000067890') C
FROM dual
단순히 데이터를 '12345'에서 '54321' 로 변경했다. 결과가 어떻게 나올까?
아마도 B에서 복잡하게 느껴지는 사람이 많을 것 같다. 따라서 B를 기준으로 설명하겠다.
여기서 핵심은 검색문자와 치환문자 변경 규칙은 위치, 즉 인덱스에 정확히 대응된다는 것을 염두하자
public class CharEx {
public static void main(String[] args) {
for(char a = 65; a < 91 ; a ++) {
System.out.print(a+",");
}
}
}
// 결과 : A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,
public class Var {
static int classVariable;
int instanceVariable;
//main()도 메서드이므로 로컬영역이다.
public static void main(String[] args) {
VarEx1 instance = new VarEx1();
int localVariable;
System.out.println(classVariable);
System.out.println(instance.instanceVariable);
// System.out.println(localVariable);
}
}
기본형 인스턴스 변수와 클래스 변수는 각각 정해진 기본값으로 초기화가 자동으로 된다.
기본형 지역변수는 선언과 동시에 초기화를 반드시 해야한다.
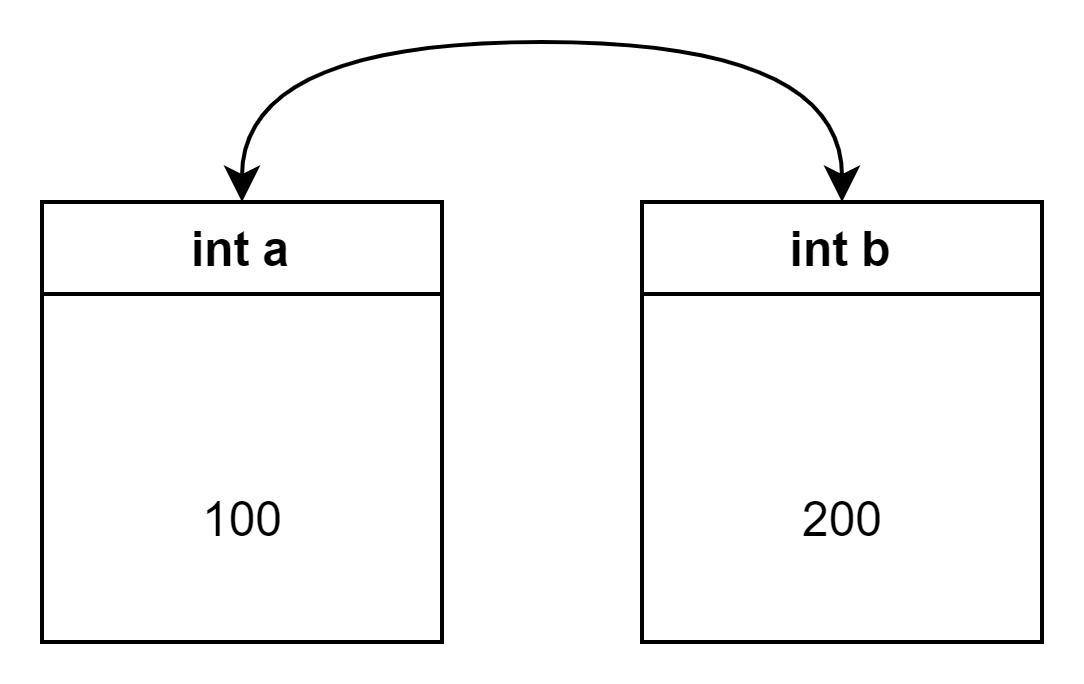
두 변수의 값 교환하기
현실의사고방식으로는바꿔치지를생각할수있지만여기는기계속이다. 불가능하다.
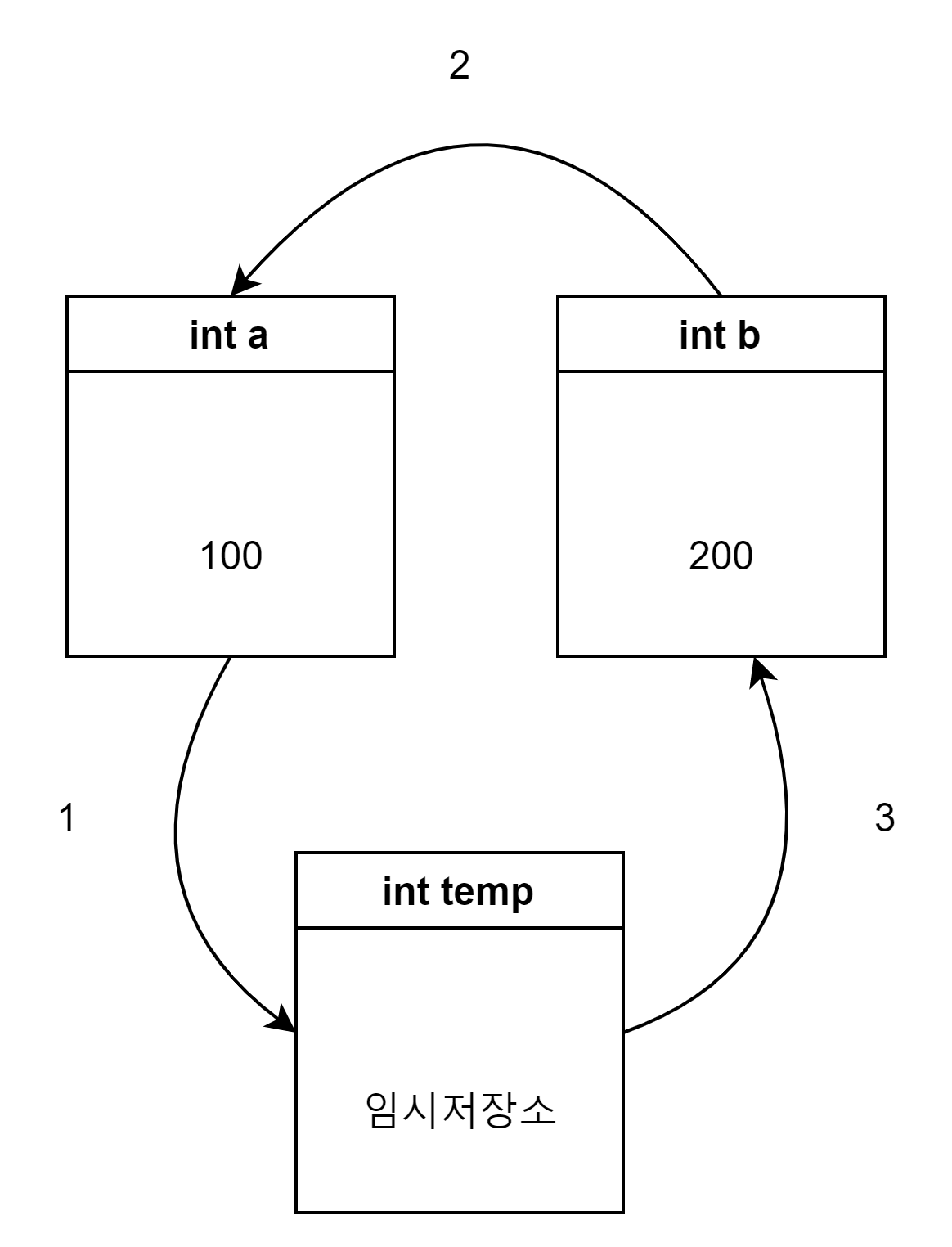
먼저 a를 temp에임시저장한다
a 자리에 b 값을넣는다.
b 자리에 temp 값을넣는다.
물컵두잔에내용물을바꾼다고생각하면쉽다.
아니면실제로코드상으로변수 2개로만바꿀려고시도해보자. 그러면 왜 temp가 필요한지이해가잘된다.