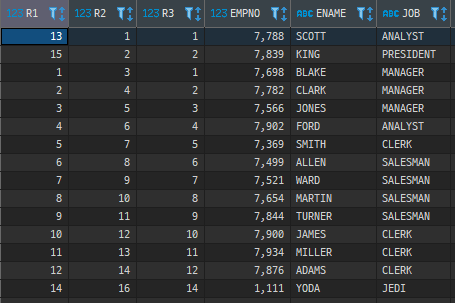
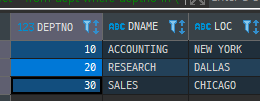
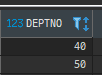
SELECT * FROM DEPT WHERE DEPTNO IN (10,20,30)
UNION ALL
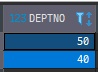
SELECT * FROM DEPT WHERE DEPTNO IN (30,40,50);
SELECT * FROM DEPT WHERE DEPTNO IN (10,20,30)
UNION
SELECT * FROM DEPT WHERE DEPTNO IN (30,40,50)
----------------------------------------------
WITH TMP AS
(
SELECT * FROM DEPT WHERE DEPTNO IN (10,20,30)
UNION ALL
SELECT * FROM DEPT WHERE DEPTNO IN (30,40,50)
)
SELECT DISTINCT * FROM TMP ORDER BY DEPTNO
차이점은 중복 제거 여부다.
따라서 나온 결과에 DISTINCT 를 먹인 것과 같다.
만약 중복제거가 불필요하다면 UNION ALL을 사용해 불필요한 연산을 피하는 것이 좋다.
WITH VIEW_TMP AS
(
SELECT NULL AS V1 FROM dual
)
SELECT CASE WHEN V1 = NULL THEN 'NULL입니다' END AS T1
, CASE WHEN V1 IS NULL THEN 'NULL입니다' END AS T2
, CASE V1 WHEN NULL THEN 'NULL입니다' END AS T3
-- , CASE V1 WHEN IS NULL THEN 'NULL입니다' END AS T4 문법 오류
, DECODE(V1, NULL, 'NULL입니다') AS T5
-- , DECODE(V1, IS NULL, 'NULL입니다') AS T6 문법 오류
FROM VIEW_TMP
UNION ALL
SELECT CASE WHEN V1 != NULL THEN 'NULL아닙니다' END AS T1
, CASE WHEN V1 IS NOT NULL THEN 'NULL아닙니다' END AS T2
, CASE V1 WHEN /*NOT*/ NULL THEN 'NULL아닙니다' END AS T3 --문법 오류
-- , CASE V1 WHEN IS NULL THEN 'NULL아닙니다' END AS T4 문법 오류
, DECODE(V1,/*NOT*/ NULL, 'NULL입니다') AS T5 --문법 오류
-- , DECODE(V1, IS NULL, 'NULL아닙니다') AS T6 문법 오류
FROM VIEW_TMP;
CASE WHEN 과 DECODE 가 NULL 다루는 방법이 다르다.
CASE WHEN은 키워드를 통한 NULL처리가 아닌 연산자를 통한 연산 시 흔히 생각하는 값이 안나온다.
CASE WHEN에서 NULL을 다룰 때는 무조건 키워드로 다뤄야 한다는 것만 기억하면 된다.
통계 쿼리를 낼 때 NULL을 다루다 위를 차이점을 모르면 전혀 다른 결과를 낼 수 있기 때문에 주의해야한다.
SELECT DATA
, TRANSLATE (DATA, ' 1234567890', ' ') AS "숫자만제거"
, TRANSLATE (DATA, '1234567890'||DATA, '1234567890') AS "숫자만남기기"
, TRANSLATE (LOWER(DATA), ' abcdefghijklmnopqrstuvwxyz' , ' ' ) AS "문자만제거"
, TRANSLATE (LOWER(DATA), 'abcdefghijklmnopqrstuvwxyz'||DATA , 'abcdefghijklmnopqrstuvwxyz' ) AS "문자만남기기"
FROM (SELECT EMPNO||ENAME||HIREDATE AS DATA
FROM EMP )
DATA
숫자만제거
숫자만남기기
문자만제거
문자만남기기
7698BLAKE81/05/01
BLAKE//
7698810501
769881/05/01
blake
7782CLARK81/06/09
CLARK//
7782810609
778281/06/09
clark
7566JONES81/04/02
JONES//
7566810402
756681/04/02
jones
7902FORD81/12/03
FORD//
7902811203
790281/12/03
ford
7369SMITH80/12/17
SMITH//
7369801217
736980/12/17
smith
7499ALLEN81/02/20
ALLEN//
7499810220
749981/02/20
allen
7521WARD81/02/22
WARD//
7521810222
752181/02/22
ward
7654MARTIN81/09/28
MARTIN//
7654810928
765481/09/28
martin
7844TURNER81/09/08
TURNER//
7844810908
784481/09/08
turner
7900JAMES81/12/03
JAMES//
7900811203
790081/12/03
james
7934MILLER82/01/23
MILLER//
7934820123
793482/01/23
miller
7876ADAMS87/05/23
ADAMS//
7876870523
787687/05/23
adams
7788SCOTT87/04/19
SCOTT//
7788870419
778887/04/19
scott
1111YODA81/11/17
YODA//
1111811117
111181/11/17
yoda
7839KING81/11/17
KING//
7839811117
783981/11/17
king
TRANSLATE 만 이해하면 문자열 다루는 함수는 거의 다 이해한 것이나 다름이 없다.
TRANSLATE( 데이터, 검색문자 , 치환문자)
문제
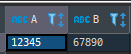
SELECT TRANSLATE ('abcde', '1234567890', ' ') FROM DUAL
정답은?
'abcde' 그대로 출력된다. '1234567890' 로 검색해서 일치하는 것이 없기 때문이다.
문제
SELECT TRANSLATE ('12345', '1234567890', '12345') A
, TRANSLATE ('12345', '1234567890', '67890') B
FROM dual
A,B 결과는?
여기서 중요한 것은 A도 똑같지만 특히 B가 왜 '67890'이라는 결과가 나왔는지다
'1234567890' 에서 '67890' 이 있으니까 '67890' 나왔다고 생각했다면 틀렸다.
SELECT TRANSLATE ('12345', '1234567890', '12345') A
, TRANSLATE ('12345', '1234567890', '67890') B
, TRANSLATE ('12345', '1234567890', '0000067890') C
FROM dual
C가 어떤 결과가 나올 것 같은가?
답은 '00000' 이다.
즉, 앞서 A 도 '12345' 가 '12345' 가 그대로 출력된게 아니라 치환되어 '12345'가 된것으로 값이 잘 맞아 떨어져 그대로 출력하게 된 것 처럼 보인 것이다.
즉, A, B 다 치환된 결과이다.
'1234567890' 검색문자가 어떻게 치환되는지 알아보자
문제
SELECT TRANSLATE ('54321', '1234567890', '12345') A
, TRANSLATE ('54321', '1234567890', '67890') B
, TRANSLATE ('54321', '1234567890', '0000067890') C
FROM dual
단순히 데이터를 '12345'에서 '54321' 로 변경했다. 결과가 어떻게 나올까?
아마도 B에서 복잡하게 느껴지는 사람이 많을 것 같다. 따라서 B를 기준으로 설명하겠다.
여기서 핵심은 검색문자와 치환문자 변경 규칙은 위치, 즉 인덱스에 정확히 대응된다는 것을 염두하자
/*1차 필요한 컬럼 값 만들기*/
SELECT
LEVEL AS "DAY"
,TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'DD') AS "TO_CHAR"
,EXTRACT(DAY FROM TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1) AS "EXTRACT"
,TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD') AS "마지막일"
,TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') AS "요일 인덱스"
,TRUNC(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') AS "내가 속한날 첫 일"
FROM DUAL
CONNECT BY LEVEL <=TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD');
"DAY", "TO_CHAR", "EXTRACT" 는 같은 값을 다르게 뽑는 방식입니다.
추가로 오른쪽 정렬이 숫자, 왼쪽 정렬이 문자열을 의미합니다.
보통 모든 변환은 TO_CHAR를 제일 많이 사용합니다. 지원하는 기능도 많고 문자열이기 때문에 매개체 역할도 가능하기 때문입니다.
/*DECODE 사용한 피벗 */
SELECT
"내가 속한날 첫 일"
,DECODE("요일 인덱스", 1 , "DAY") AS "일"
,DECODE("요일 인덱스", 2 , "DAY") AS "월"
,DECODE("요일 인덱스", 3 , "DAY") AS "화"
,DECODE("요일 인덱스", 4 , "DAY") AS "수"
,DECODE("요일 인덱스", 5 , "DAY") AS "목"
,DECODE("요일 인덱스", 6 , "DAY") AS "금"
,DECODE("요일 인덱스", 7 , "DAY") AS "토"
FROM
(
SELECT
LEVEL AS "DAY"
,TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'DD') AS "TO_CHAR"
,EXTRACT(DAY FROM TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1) AS "EXTRACT"
,TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD') AS "마지막일"
,TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') "요일 인덱스"
,TRUNC(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') AS "내가 속한날 첫 일"
FROM DUAL
CONNECT BY LEVEL <=TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD')
)
ORDER BY DAY
;
/*GROUP BY 내가 속한날 첫 일_ 로 컬럼 값 압축*/
SELECT
"내가 속한날 첫 일"
,SUM(DECODE("요일 인덱스", 1 , "DAY")) AS "일"
,MIN(DECODE("요일 인덱스", 2 , "DAY")) AS "월"
,MAX(DECODE("요일 인덱스", 3 , "DAY")) AS "화"
,SUM(DECODE("요일 인덱스", 4 , "DAY")) AS "수"
,MIN(DECODE("요일 인덱스", 5 , "DAY")) AS "목"
,MAX(DECODE("요일 인덱스", 6 , "DAY")) AS "금"
,SUM(DECODE("요일 인덱스", 7 , "DAY")) AS "토"
FROM
(
SELECT
LEVEL AS "DAY"
,TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'DD') AS "TO_CHAR"
,EXTRACT(DAY FROM TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1) AS "EXTRACT"
,TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD') AS "마지막일"
,TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') "요일 인덱스"
,TRUNC(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') AS "내가 속한날 첫 일"
FROM DUAL
CONNECT BY LEVEL <=TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD')
)
GROUP BY "내가 속한날 첫 일"
ORDER BY MIN(DAY)
;
마지막으로 인라인뷰 없이 똑같은 결과를 만들기입니다.
위 SQL을 기반으로 만들어 보기실 권장합니다.
*인라인뷰 사용 안한 최종 쿼리*/
SELECT
TRUNC(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D') AS "내가 속한날 첫 일"
,SUM(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 1 , LEVEL)) AS "일"
,MIN(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 2 , LEVEL)) AS "월"
,MAX(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 3 , LEVEL)) AS "화"
,SUM(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 4 , LEVEL)) AS "수"
,MIN(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 5 , LEVEL)) AS "목"
,MAX(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 6 , LEVEL)) AS "금"
,SUM(DECODE(TO_CHAR(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D'), 7 , LEVEL)) AS "토"
FROM DUAL
CONNECT BY LEVEL <=TO_CHAR(TO_DATE(:ST_YYYYMM+1, 'YYYYMM')-1, 'DD')
GROUP BY TRUNC(TO_DATE(:ST_YYYYMM, 'YYYYMM')+LEVEL-1, 'D')
ORDER BY MIN(LEVEL)
;