import java.util.*;
class K번째큰수_ {
public static void main(String[] args){
int[] arr = new Random().ints(100, 1, 101)
.toArray();
int k = 4; //번째 큰수
int n = arr.length;
int count =0;
// 역순 정렬을 위해 직접 Comparator 구현
TreeSet<Integer> set = new TreeSet<>((a,b)->Integer.compare(b, a));
for(int i = 0;i<n;i++) {
for(int j=i+1;j<n;j++) {
for(int z=j+1;z<n;z++) {
set.add(arr[i]+arr[j]+arr[z]);
count++;
}
}
}
//사이즈를 넘어선 k는 예외발생
if(set.size()<k) {
System.out.println("-1 not found");
}
int cnt = 1;
int sum = 0;
for(Iterator<Integer> it = set.iterator();it.hasNext() ;cnt++) {
sum = it.next();
System.out.print(sum+",");
if(cnt==k) {
System.out.println("\n"+k+"번째 큰 수 : "+ sum);;
break;
}
}
System.out.println("경우의 수 : " +count);
}
}
class Solution {
public boolean solution(String[] phone_book) {
/**
* 정렬을 한다.
* 기대효과, 배열 요소 두 항을 비교 시
* 어느쪽이 더 작은지에 대한 조건을 제거할 수 있다.
*/
Arrays.sort(phone_book);
//항상 i+1은 i 크거나 같다.
for(int i=0;i<phone_book.length-1;i++) {
if(phone_book[i+1].substring(0, phone_book[i].length()).equals(phone_book[i])){
return false;
}
}
return true;
}
}
풀고나니, 이 문제의 분류가.. 해시인 것을 발견했다.
자바의 해시알고리즘을 사용하는 컬렉션인 HashMap을 사용!
class Solution {
public boolean solution(String[] phone_book) {
Map<String, Integer> map = new HashMap<String, Integer>();
for (int i = 0; i < phone_book.length; i++) {
map.put(phone_book[i], 1);
}
// String 배열을 순회한다.
for (int i = 0; i < phone_book.length; i++) {
// String은 사실 char[]에 요긴한 메서드를 덧분인 일종의 Wrapper 클래스이다.
for (int j = 0; j < phone_book[i].length(); j++) {
//따라서, substring() 결과는 아래와 같다.
if (map.containsKey(phone_book[i].substring(0, j))) {
// if(map.containsKey(String.valueOf(Arrays.copyOfRange(phone_book[i].toCharArray(),0, j)) )) {
return false;
}
}
}
return true;
}
}
핵심은 cotainsKey()메서드가 아니라, 해시 알고리즘을 사용하는 컬렉션의 데이터 접근시간에 대한 이해인 것 같다.
자바에서 Hash- 접두어로 붙은 컬렉션은 해시 알고리즘을 사용한다.
위 HashMap의 경우 key를 해시 알고리즘을 돌려 그 결과를 key로 사용한다.
자바에서 해시를 이용한 컬렉션을 사용하는 이유는 내가 알기론 일종의 절충안이다.
기존 자료구조인 배열은 접근시간이 어느 위치나 똑같다. ( 배열 시작 주소 + DataType 사이즈 * n)
하지만 변경에 취약한 구조이다. 배열은 빈공간을 허용하지 않기 때문에 중간에 자료를 제거한 순간 대규모 자리이동이 발생한다.
배열
4번의 자리이동이 발생한다.
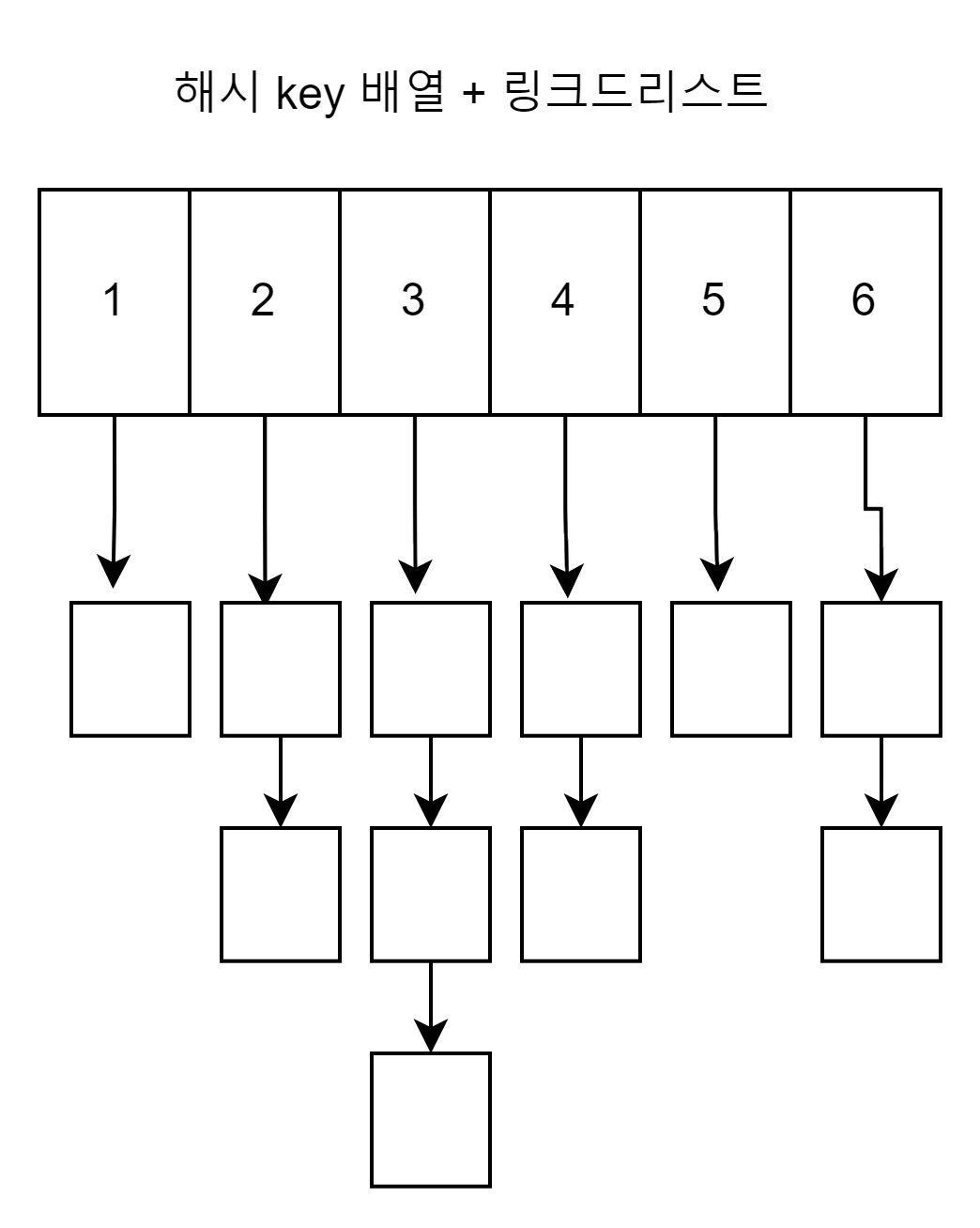
이를 극복한 것이 링크드 리스트이다. 하지만 링크드리스트는 배열과 정반대로 접근시간이 배열보다 느리다.
이유는 계산식이 아닌 해당 위치까지 내 다음 노드를 타고타고 가야하기 때문이다.
대신 배열에 약점인 변경에 강하다. 노드 주소만 수정하면 그만이다.
삭제는 한 번의 주소 수정이면 끝나고, 삽입은 두 번의 주소 수정이면 끝난다.
해시를 이용한 컬렉션은 key로 해시 알고리즘 값을 사용하기 때문에 어느 위치던 거의 동일한 접근시간을 보장한다.
public class Main {
static int a=0;
public static void main(String[] args) {
new Random().ints(1, 200)
.distinct()
.limit(100)
.boxed()
.collect(groupingBy( k->k ))
.forEach( (k,v) -> {
a++;
if(a%10 == 1) {
System.out.println();
}
System.out.printf("%4s",k);
});
System.out.println();
System.out.println("---------해시알고리즘을 사용하면 항상 같은 위치에 값을 저장해서 잘 안섞입니다.---------");
new Random().ints(1, 200)
.distinct()
.limit(100)
.boxed()
.collect(toList())
.forEach( k -> {
a++;
if(a%10 == 1) {
System.out.println();
}
System.out.printf("%4s",k);
});
}
}