Clean Code(클린 코드) | 로버트 C. 마틴 | 인사이트- 교보ebook
애자일 소프트웨어 장인 정신, 나쁜 코드도 돌아는 간다. 하지만 코드가 깨끗하지 못하면 개발 조직은 기어간다. 매년 지저분한 코드로 수많은 시간과 상당한 자원이 낭비된다. 그래야 할 이유
ebook-product.kyobobook.co.kr
코드
https://github.com/rkwhr0010/clean_code/tree/main/src
변경 사항은 git history 참고
저자가 신경 쓴 예제 코드로 구조를 면밀히 살핀다.
명령행 인수 구문을 분석하는 프로그램 Args
Args는 생성자로 인수 형식 문자열과 명령행 인수를 받는다.
Args인스턴스로 인수 값을 질의한다.
| public class Main { public static void main(String[] args) { try { Args arg = new Args("l,p#,d*", args); boolean logging = arg.getBoolean('l'); // 불린 int port = arg.getInt('p'); // 정수 String directory = arg.getString('d'); // 문자열 executeApplication(logging, port, directory); } catch (ArgsException e) { System.out.printf("Argument error: %s\n", e.errorMessage()); } } private static void executeApplication(boolean logging, int port, String directory) { /* 예제 없음....*/ } } |
Args 구현
| package chap14.ex01; import static chap14.ex01.ArgsException.ErrorCode.*; import java.util.*; public class Args { private Map<Character, ArgumentMarshaler> marshalers; private Set<Character> argsFound; private ListIterator<String> currentArgument; public Args(String schema, String[] args) throws ArgsException { marshalers = new HashMap<Character, ArgumentMarshaler>(); argsFound = new HashSet<Character>(); parseSchema(schema); parseArgumentStrings(Arrays.asList(args)); } private void parseSchema(String schema) throws ArgsException { for (String element : schema.split(",")) if (element.length() > 0) parseSchemaElement(element.trim()); } private void parseSchemaElement(String element) throws ArgsException { char elementId = element.charAt(0); String elementTail = element.substring(1); validateSchemaElementId(elementId); if (elementTail.length() == 0) marshalers.put(elementId, new BooleanArgumentMarshaler()); else if (elementTail.equals("*")) marshalers.put(elementId, new StringArgumentMarshaler()); else if (elementTail.equals("#")) marshalers.put(elementId, new IntegerArgumentMarshaler()); else if (elementTail.equals("##")) marshalers.put(elementId, new DoubleArgumentMarshaler()); else if (elementTail.equals("[*]")) marshalers.put(elementId, new StringArrayArgumentMarshaler()); else throw new ArgsException(INVALID_ARGUMENT_FORMAT, elementId, elementTail); } private void validateSchemaElementId(char elementId) throws ArgsException { if (!Character.isLetter(elementId)) throw new ArgsException(INVALID_ARGUMENT_NAME, elementId, null); } private void parseArgumentStrings(List<String> argsList) throws ArgsException { for (currentArgument = argsList.listIterator(); currentArgument.hasNext();) { String argString = currentArgument.next(); if (argString.startsWith("-")) { parseArgumentCharacters(argString.substring(1)); } else { currentArgument.previous(); break; } } } private void parseArgumentCharacters(String argChars) throws ArgsException { for (int i = 0; i < argChars.length(); i++) parseArgumentCharacter(argChars.charAt(i)); } private void parseArgumentCharacter(char argChar) throws ArgsException { ArgumentMarshaler m = marshalers.get(argChar); if (m == null) { throw new ArgsException(UNEXPECTED_ARGUMENT, argChar, null); } else { argsFound.add(argChar); try { m.set(currentArgument); } catch (ArgsException e) { e.setErrorArgumentId(argChar); throw e; } } } public boolean has(char arg) { return argsFound.contains(arg); } public int nextArgument() { return currentArgument.nextIndex(); } public boolean getBoolean(char arg) { return BooleanArgumentMarshaler.getValue(marshalers.get(arg)); } public String getString(char arg) { return StringArgumentMarshaler.getValue(marshalers.get(arg)); } public int getInt(char arg) { return IntegerArgumentMarshaler.getValue(marshalers.get(arg)); } public double getDouble(char arg) { return DoubleArgumentMarshaler.getValue(marshalers.get(arg)); } public String[] getStringArray(char arg) { return StringArrayArgumentMarshaler.getValue(marshalers.get(arg)); } } |
구조가 위에서 아래로 읽힌다. 스크롤을 사용해 이리저리 이동하지 않는다.
| import java.util.*; public interface ArgumentMarshaler { void set(Iterator<String> currentArgument) throws ArgsException; } |
| public class BooleanArgumentMarshaler implements ArgumentMarshaler { private boolean booleanValue = false; public void set(Iterator<String> currentArgument) throws ArgsException { booleanValue = true; } public static boolean getValue(ArgumentMarshaler am) { if (am != null && am instanceof BooleanArgumentMarshaler) return ((BooleanArgumentMarshaler) am).booleanValue; else return false; } } |
| import static chap14.ex01.ArgsException.ErrorCode.*; import java.util.*; public class StringArgumentMarshaler implements ArgumentMarshaler { private String stringValue = ""; public void set(Iterator<String> currentArgument) throws ArgsException { try { stringValue = currentArgument.next(); } catch (NoSuchElementException e) { throw new ArgsException(MISSING_STRING); } } public static String getValue(ArgumentMarshaler am) { if (am != null && am instanceof StringArgumentMarshaler) return ((StringArgumentMarshaler) am).stringValue; else return ""; } } |
| import static chap14.ex01.ArgsException.ErrorCode.*; import java.util.*; public class IntegerArgumentMarshaler implements ArgumentMarshaler { private int intValue = 0; public void set(Iterator<String> currentArgument) throws ArgsException { String parameter = null; try { parameter = currentArgument.next(); intValue = Integer.parseInt(parameter); } catch (NoSuchElementException e) { throw new ArgsException(MISSING_INTEGER); } catch (NumberFormatException e) { throw new ArgsException(INVALID_INTEGER, parameter); } } public static int getValue(ArgumentMarshaler am) { if (am != null && am instanceof IntegerArgumentMarshaler) return ((IntegerArgumentMarshaler) am).intValue; else return 0; } } |
| import static chap14.ex01.ArgsException.ErrorCode.*; import java.util.*; public class DoubleArgumentMarshaler implements ArgumentMarshaler { private double doubleValue = 0; public void set(Iterator<String> currentArgument) throws ArgsException { String parameter = null; try { parameter = currentArgument.next(); doubleValue = Double.parseDouble(parameter); } catch (NoSuchElementException e) { throw new ArgsException(MISSING_DOUBLE); } catch (NumberFormatException e) { throw new ArgsException(INVALID_DOUBLE, parameter); } } public static double getValue(ArgumentMarshaler am) { if (am != null && am instanceof DoubleArgumentMarshaler) return ((DoubleArgumentMarshaler) am).doubleValue; else return 0.0; } } |
| import static chap14.ex01.ArgsException.ErrorCode.*; import java.util.*; public class StringArrayArgumentMarshaler implements ArgumentMarshaler { private List<String> strings = new ArrayList<String>(); public void set(Iterator<String> currentArgument) throws ArgsException { try { strings.add(currentArgument.next()); } catch (NoSuchElementException e) { throw new ArgsException(MISSING_STRING); } } public static String[] getValue(ArgumentMarshaler am) { if (am != null && am instanceof StringArrayArgumentMarshaler) return ((StringArrayArgumentMarshaler) am).strings.toArray(new String[0]); else return new String[0]; } } |
오류 코드
| import static chap14.ex01.ArgsException.ErrorCode.*; @SuppressWarnings("serial") public class ArgsException extends Exception { private char errorArgumentId = '\0'; private String errorParameter = null; private ErrorCode errorCode = OK; public ArgsException() { } public ArgsException(String message) { super(message); } public ArgsException(ErrorCode errorCode) { this.errorCode = errorCode; } public ArgsException(ErrorCode errorCode, String errorParameter) { this.errorCode = errorCode; this.errorParameter = errorParameter; } public ArgsException(ErrorCode errorCode, char errorArgumentId, String errorParameter) { this.errorCode = errorCode; this.errorParameter = errorParameter; this.errorArgumentId = errorArgumentId; } public char getErrorArgumentId() { return errorArgumentId; } public void setErrorArgumentId(char errorArgumentId) { this.errorArgumentId = errorArgumentId; } public String getErrorParameter() { return errorParameter; } public void setErrorParameter(String errorParameter) { this.errorParameter = errorParameter; } public ErrorCode getErrorCode() { return errorCode; } public void setErrorCode(ErrorCode errorCode) { this.errorCode = errorCode; } public String errorMessage() { switch (errorCode) { case OK: return "TILT: Should not get here."; case UNEXPECTED_ARGUMENT: return String.format("Argument -%c unexpected.", errorArgumentId); case MISSING_STRING: return String.format("Could not find string parameter for -%c.", errorArgumentId); case INVALID_INTEGER: return String.format("Argument -%c expects an integer but was '%s'.", errorArgumentId, errorParameter); case MISSING_INTEGER: return String.format("Could not find integer parameter for -%c.", errorArgumentId); case INVALID_DOUBLE: return String.format("Argument -%c expects a double but was '%s'.", errorArgumentId, errorParameter); case MISSING_DOUBLE: return String.format("Could not find double parameter for -%c.", errorArgumentId); case INVALID_ARGUMENT_NAME: return String.format("'%c' is not a valid argument name.", errorArgumentId); case INVALID_ARGUMENT_FORMAT: return String.format("'%s' is not a valid argument format.", errorParameter); } return ""; } public enum ErrorCode { OK, INVALID_ARGUMENT_FORMAT, UNEXPECTED_ARGUMENT, INVALID_ARGUMENT_NAME, MISSING_STRING, MISSING_INTEGER, INVALID_INTEGER, MISSING_DOUBLE, INVALID_DOUBLE } } |
단순한 개념이나 코드가 많은 이유는 자바는 정적 타입 언어이기 때문이다.
동적 타입 언어라면 코드량은 획기적으로 줄어든다.
저자가 공들인 예제로 천천히 꼼꼼히 보는 것이 좋다.
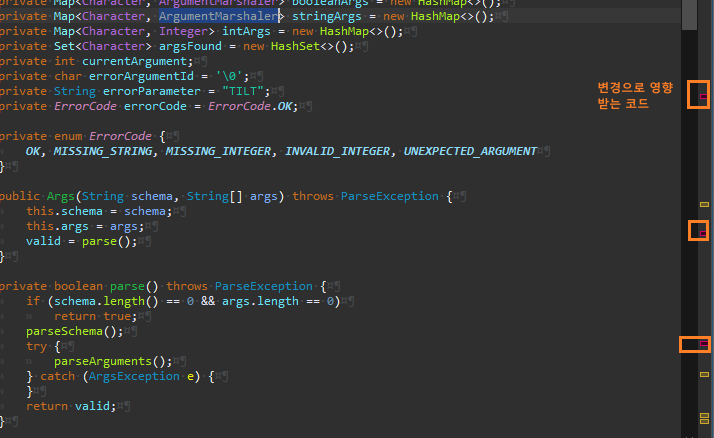
이름, 함수 크기, 코드 형식, 새로운 코드 추가 시 기존 코드에 거의 영향 없음(팩토리 같은 코드에만 영향)
어떻게 짰느냐고?
한 번에 위와 같은 깥끔한 코드를 구현하는 것은 전문가도 불가능하다.
깨끗한 코드를 짜려면 먼저 지저분한 코드를 짠 뒤 정리해야 한다.
문서에 초안을 작성하고, 퇴고하는 것과 같다.
개발도, 일단 목적에 맞는 돌아가는 코드를 목표로 하고, 그 이후 정리를 한다.
대부분의 개발자는 돌아만 가는 코드만 구현하고 정리를 하지 않는다.
Args: 1차 초안
| import java.text.ParseException; import java.util.*; public class Args { private String schema; private String[] args; private boolean valid = true; private Set<Character> unexpectedArguments = new TreeSet<>(); private Map<Character, Boolean> booleanArgs = new HashMap<>(); private Map<Character, String> stringArgs = new HashMap<>(); private Map<Character, Integer> intArgs = new HashMap<>(); private Set<Character> argsFound = new HashSet<>(); private int currentArgument; private char errorArgumentId = '\0'; private String errorParameter = "TILT"; private ErrorCode errorCode = ErrorCode.OK; private enum ErrorCode { OK, MISSING_STRING, MISSING_INTEGER, INVALID_INTEGER, UNEXPECTED_ARGUMENT } public Args(String schema, String[] args) throws ParseException { this.schema = schema; this.args = args; valid = parse(); } private boolean parse() throws ParseException { if (schema.length() == 0 && args.length == 0) return true; parseSchema(); try { parseArguments(); } catch (ArgsException e) { } return valid; } private boolean parseSchema() throws ParseException { for (String element : schema.split(",")) { if (element.length() > 0) { String trimmedElement = element.trim(); parseSchemaElement(trimmedElement); } } return true; } private void parseSchemaElement(String element) throws ParseException { char elementId = element.charAt(0); String elementTail = element.substring(1); validateSchemaElementId(elementId); if (isBooleanSchemaElement(elementTail)) parseBooleanSchemaFlement(elementId); else if (isStringSchemaElement(elementTail)) parseStringSchemaFlement(elementId); else if (isIntegerSchemaElement(elementTail)) { parseIntegerSchemaFlement(elementId); } else { throw new ParseException(String.format("Argument: %c has invalid format: %s.", elementId, elementTail), 0); } } private void validateSchemaElementId(char elementId) throws ParseException { if (!Character.isLetter(elementId)) { throw new ParseException("Bad character:" + elementId + "in Args format: " + schema, 0); } } private void parseBooleanSchemaFlement(char elementId) { booleanArgs.put(elementId, false); } private void parseIntegerSchemaFlement(char elementId) { intArgs.put(elementId, 0); } private void parseStringSchemaFlement(char elementId) { stringArgs.put(elementId, ""); } private boolean isStringSchemaElement(String elementTail) { return elementTail.equals("*"); } private boolean isBooleanSchemaElement(String elementTail) { return elementTail.length() == 0; } private boolean isIntegerSchemaElement(String elementTail) { return elementTail.equals("#"); } private boolean parseArguments() throws ArgsException { for (currentArgument = 0; currentArgument < args.length; currentArgument++) { String arg = args[currentArgument]; parseArgument(arg); } return true; } private void parseArgument(String arg) throws ArgsException { if (arg.startsWith("-")) parseElements(arg); } private void parseElements(String arg) throws ArgsException { for (int i = 1; i < arg.length(); i++) parseElement(arg.charAt(i)); } private void parseElement(char argChar) throws ArgsException { if (setArgument(argChar)) argsFound.add(argChar); else { unexpectedArguments.add(argChar); errorCode = ErrorCode.UNEXPECTED_ARGUMENT; valid = false; } } private boolean setArgument(char argChar) throws ArgsException { if (isBooleanArg(argChar)) setBooleanArg(argChar, true); else if (isStringArg(argChar)) setStringArg(argChar); else if (isIntArg(argChar)) setIntArg(argChar); else return false; return true; } private boolean isIntArg(char argChar) { return intArgs.containsKey(argChar); } private void setIntArg(char argChar) throws ArgsException { currentArgument++; String parameter = null; try { parameter = args[currentArgument]; intArgs.put(argChar, new Integer(parameter)); } catch (ArrayIndexOutOfBoundsException e) { valid = false; errorArgumentId = argChar; errorCode = ErrorCode.MISSING_INTEGER; throw new ArgsException(); } catch (NumberFormatException e) { valid = false; errorArgumentId = argChar; errorParameter = parameter; errorCode = ErrorCode.INVALID_INTEGER; throw new ArgsException(); } } private void setStringArg(char argCha) throws ArgsException { currentArgument++; try { stringArgs.put(argCha, args[currentArgument]); } catch (ArrayIndexOutOfBoundsException e) { valid = false; errorArgumentId = argCha; errorCode = ErrorCode.MISSING_STRING; throw new ArgsException(); } } private boolean isStringArg(char argChar) { return stringArgs.containsKey(argChar); } private void setBooleanArg(char argChar, boolean value) { booleanArgs.put(argChar, value); } private boolean isBooleanArg(char argChar) { return booleanArgs.containsKey(argChar); } public int cardinality() { return argsFound.size(); } public String usage() { if (schema.length() > 0) return "-[" + schema + "]"; else return ""; } public String errorMessage() throws Exception { switch (errorCode) { case OK: throw new Exception("TILT: Should not get here."); case UNEXPECTED_ARGUMENT: return unexpectedArgumentMessage(); case MISSING_STRING: return String.format("Could not find string parameter for -%c.", errorArgumentId); case INVALID_INTEGER: return String.format("Argument -%c expects an integer but was '%s'.", errorArgumentId, errorParameter); case MISSING_INTEGER: return String.format("Could not find integer parameter for -%c.", errorArgumentId); } return ""; } private String unexpectedArgumentMessage() { StringBuffer message = new StringBuffer("Argument(s) -"); for (char c : unexpectedArguments) { message.append(c); } message.append(" unexpected."); return message.toString(); } private boolean falseIfNull(Boolean b) { return b != null && b; } private int zeroIfNull(Integer i) { return i == null ? 0 : i; } private String blankIfNull(String s) { return s == null ? "" : s; } public String getString(char arg) { return blankIfNull(stringArgs.get(arg)); } public int getInt(char arg) { return zeroIfNull(intArgs.get(arg)); } public boolean getBoolean(char arg) { return falseIfNull(booleanArgs.get(arg)); } public boolean has(char arg) { return argsFound.contains(arg); } public boolean isValid() { return valid; } private class ArgsException extends Exception { } } |
1차 초안은 말장난이다. 사실 미완성이다.
인스턴스 변수 수도 많고, 'TILT' 은 의미도 해석할 수 없다.
최초 Boolean 인수만 지원하던 초기 버전
| package chap14.ex03; import java.util.*; public class Args { private String schema; private String[] args; private boolean valid; private Set<Character> unexpectedArguments = new TreeSet<>(); private Map<Character, Boolean> booleanArgs = new HashMap<>(); private int numberOfArguments = 0; public Args(String schema, String[] args) { this.schema = schema; this.args = args; valid = parse(); } public boolean isValid() { return valid; } private boolean parse() { if (schema.length() == 0 && args.length == 0) return true; parseSchema(); parseArguments(); return unexpectedArguments.size() == 0; } private boolean parseSchema() { for (String element : schema.split(",")) { parseSchemaElement(element); } return true; } private void parseSchemaElement(String element) { parseBooleanSchemaFlement(element); } private void parseBooleanSchemaFlement(String element) { char c = element.charAt(0); if (Character.isLetter(c)) { booleanArgs.put(c, false); } } private boolean parseArguments() { for (String arg : args) parseArgument(arg); return true; } private void parseArgument(String arg) { if (arg.startsWith("-")) parseElements(arg); } private void parseElements(String arg) { for (int i = 1; i < arg.length(); i++) parseElement(arg.charAt(i)); } private void parseElement(char argChar) { if (isBoolean(argChar)) { numberOfArguments++; setBooleanArg(argChar, true); } else unexpectedArguments.add(argChar); } private boolean isBoolean(char argChar) { return booleanArgs.containsKey(argChar); } private void setBooleanArg(char argChar, boolean value) { booleanArgs.put(argChar, value); } public int cardinality() { return numberOfArguments; } public String usage() { if (schema.length() > 0) return "-[" + schema + "]"; else return ""; } public String errorMessage() { if (unexpectedArguments.size() > 0) { return unexpectedArgumentMessage(); } else return ""; } private String unexpectedArgumentMessage() { StringBuffer message = new StringBuffer("Argument(s) -"); for (char c : unexpectedArguments) { message.append(c); } message.append(" unexpected."); return message.toString(); } public boolean getBoolean(char arg) { return booleanArgs.get(arg); } } |
이 정도만 되어도 단순하고, 이해가 쉽다.
하지만 이 코드는 나중에 엉망으로 변할 여지가 숨겨져 있다.
그 이유로 코드가 점점 더러워진 것이다.
단 하나 String 기능 추가
| import java.text.ParseException; import java.util.*; public class Args { private String schema; private String[] args; private boolean valid; private Set<Character> unexpectedArguments = new TreeSet<>(); private Map<Character, Boolean> booleanArgs = new HashMap<>(); private Map<Character, String> stringArgs = new HashMap<>(); private Set<Character> argsFound = new HashSet<>(); private int currentArgument; private char errorArgument = '\0'; enum ErrorCode{ OK, MISSING_STRING } private ErrorCode errorCode = ErrorCode.OK; public Args(String schema, String[] args) throws ParseException { this.schema = schema; this.args = args; valid = parse(); } private boolean parse() throws ParseException { if (schema.length() == 0 && args.length == 0) return true; parseSchema(); parseArguments(); return valid; } private boolean parseSchema() throws ParseException { for (String element : schema.split(",")) { if (element.length() > 0) { String trimmedElement = element.trim(); parseSchemaElement(trimmedElement); } } return true; } private void parseSchemaElement(String element) throws ParseException { char elementId = element.charAt(0); String elementTail = element.substring(1); validateSchemaElementId(elementId); if (isBooleanSchemaElement(elementTail)) parseBooleanSchemaFlement(elementId); else if (isStringSchemaElement(elementTail)) parseStringSchemaFlement(elementId); } private void validateSchemaElementId(char elementId) throws ParseException { if (!Character.isLetter(elementId)) { throw new ParseException( "Bad character: " + elementId + " in Args format: " + schema, 0); } } private void parseStringSchemaFlement(char elementId) { stringArgs.put(elementId, ""); } private boolean isStringSchemaElement(String elementTail) { return elementTail.equals("*"); } private boolean isBooleanSchemaElement(String elementTail) { return elementTail.length() == 0; } private void parseBooleanSchemaFlement(char elementId) { booleanArgs.put(elementId, false); } private boolean parseArguments() { for (currentArgument = 0; currentArgument < args.length; currentArgument++) { String arg = args[currentArgument]; parseArgument(arg); } return true; } private void parseArgument(String arg) { if (arg.startsWith("-")) parseElements(arg); } private void parseElements(String arg) { for (int i = 1; i < arg.length(); i++) parseElement(arg.charAt(i)); } private void parseElement(char argChar) { if (setArgument(argChar)) argsFound.add(argChar); else { unexpectedArguments.add(argChar); } } private boolean setArgument(char argChar) { boolean set = true; if (isBoolean(argChar)) setBooleanArg(argChar, true); else if (isString(argChar)) setStringArg(argChar, ""); else set = false; return set; } private void setStringArg(char argChar, String s) { currentArgument++; try { stringArgs.put(argChar, args[currentArgument]); } catch (ArrayIndexOutOfBoundsException e) { valid = false; errorArgument = argChar; errorCode = ErrorCode.MISSING_STRING; } } private boolean isString(char argChar) { return stringArgs.containsKey(argChar); } private void setBooleanArg(char argChar, boolean value) { booleanArgs.put(argChar, value); } private boolean isBoolean(char argChar) { return booleanArgs.containsKey(argChar); } public int cardinality() { return argsFound.size(); } public String usage() { if (schema.length() > 0) return "-[" + schema + "]"; else return ""; } public String errorMessage() throws Exception{ if (unexpectedArguments.size() > 0) { return unexpectedArgumentMessage(); } else switch (errorCode) { case MISSING_STRING: return String.format("Could not find string parameter for -%c", errorArgument); case OK: throw new Exception("TILT: Should not get here."); } return ""; } private String unexpectedArgumentMessage() { StringBuffer message = new StringBuffer("Argument(s) -"); for (char c : unexpectedArguments) { message.append(c); } message.append(" unexpected."); return message.toString(); } public boolean getBoolean(char arg) { return falseIfNull(booleanArgs.get(arg)); } private boolean falseIfNull(Boolean b) { return b == null ? false : b; } public String getString(char arg) { return blankIfNull(stringArgs.get(arg)); } private String blankIfNull(String s) { return s == null ? "" : s; } public boolean has(char arg) { return argsFound.contains(arg); } public boolean isValid() { return valid; } } |
코드가 통제를 벗어나기 시작한다.
코드가 엄청나게 지저분해져 버그가 숨어들지도 모르는 코드로 변했다.
그래서 멈췄다
인수 유형이 추가되면 더욱 엉망이 된다. 그러면 더욱 유지보수하기 힘들어 진다.
리팩터링이 필요하다.
분석
신규 인수 유형 추가 시 세 곳에 코드를 추가해야 한다.
- 인수 유형 HashMap
- 명령행 인수에서 인수 유형 분석
- get*, set* 메서드
인수 유형은 다양하지만 모두가 유사한 메서드를 제공한다. 따라서 클래스 하나로 만든다. ArgumentMarchaler
점진적으로 개선하다
프로그램을 망치는 방법 중 하나는 개선이라는 이름에 아래 이전과 다르게 구조를 크게 뒤집는 행위다.
TDD(테스트 주도 개발) 기법을 사용해, 점진적으로 개선해야 한다.
TDD에선 언제라도 시스템이 돌아가야 한다.
즉, 변경 후에 변경 전과 똑같이 돌아가야 한다.
이 규칙을 준수하려면, 한 번에 크게 뜯어 고칠 수가 없다.
전과 같음을 보증하려면, 자동화된 테스트 슈트가 필요하다.
리팩터링을 하면서, 조금에 변경에도 테스트를 구동한다.
리팩터링을 하는 중 중요한 일이 생겨 그만 둬도 시스템은 전과 같이 동작할 것이다.
변경 마다 테스트를 돌렸으니까
ArgumentMarshaler 골격 추가
| /** * ###### Args 내부 ###### * 편의상 Args 내부 가장 끝 자리에 추출할 클래스를 정의했다. * 사용하지 않으니, 기존 시스템에 영향은 전혀 없다. */ private class ArgumentMarshaler { private boolean booleanValue = false; public void setBoolean(boolean value) { booleanValue = value; } public boolean getBoolean() { return booleanValue; } } private class BooleanArgumentMarshaler extends ArgumentMarshaler { } private class StringArgumentMarshaler extends ArgumentMarshaler { } private class IntegerArgumentMarshaler extends ArgumentMarshaler { } } |
점진적 변경
- 인수 유형 HashMap
- 명령행 인수에서 인수 유형 분석
- get*, set* 메서드

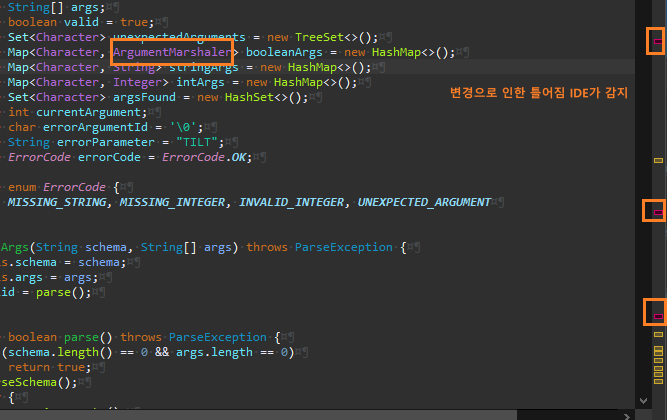
오류가 나는 곳을 수정한다.


나머지도 동일하게 알맞게 수정한다


이제 falseIfNull 메서드는 필요가 없다.
null이 존재할 수 없기 때문이다. 따라서 제거한다.


String 인수
인수 추가 시 변경될 곳
- 인수 유형 HashMap
- 명령행 인수에서 인수 유형 분석
- get*, set* 메서드

똑같이 변경하다보면, 필요한 메서드가 생긴다.
IDE의 기능을 이용해 메서드를 생성하고, 구현하면 된다.
여기서 코드가 자동 생성되는 위치가 ArgumentMarshaler 인 이유는 지네릭이 Map<Character, ArgumentMarshaler> 으로 get() 메서드로 반환되는 타입이 ArgumentMarshaler 이기 때문이다.
추가로 반대의 경우인 put()메서드로 객체를 저장할 때 서브타입은 ArgumentMarshaler로 형변환되어 저장된다.
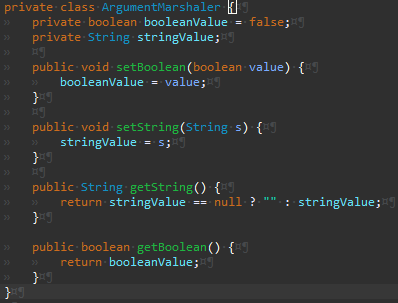
노란색 경고는 아직 호출되는 곳이 없어서 그렇다.


전과 같은 이유로 blankIfNull 메서드는 불필요하므로 제거한다.
서브 클래스가 아닌 ArgumentMarshaler 슈퍼 클래스에 일단 전부 코드를 모은 이유는 모두 기능을 옮긴 후 다시 리팩터링해 파생 클래스로 코드를 분리하기 위함이다.
과정이 늘어나지만, 더 쉽고, 더 점진적이고, 더 안전하게 리팩터링할 수 있다.
Integer도 똑같이 처리한다.


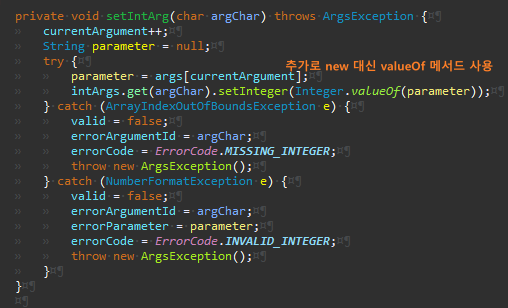

역시나 불필요한 체크 메서드를 제거했다.
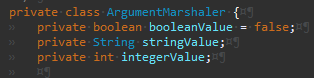
String을 제외하고 사실 기본형은 기본값으로 초기화되기 때문에 booleanValue = false도 사실 필요없다.
로직을 다 집중시킨 ArgumentMarshaler
| private class ArgumentMarshaler { private boolean booleanValue = false; private String stringValue; private int integerValue; public void setBoolean(boolean value) { booleanValue = value; } public void setInteger(int i) { integerValue = i; } public int getInteger() { return integerValue; } public void setString(String s) { stringValue = s; } public String getString() { return stringValue == null ? "" : stringValue; } public boolean getBoolean() { return booleanValue; } } |
이제 파생 클래스로 옮길 차례다.
boolean
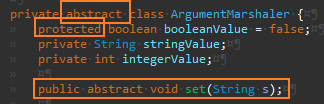
추상 클래스로 만들고 다형성 활용을 위한 추상 메서드 set을 정의한다.
그리고 옮길 대상 값을 파생 클래스에서 접근할 수 있게 protected로 변경한다.

setBoolean() 메서드를 set() 대체하도록 한다.


이제 불필요한 ArgumentMarshaler.setBoolean() 메서드를 제거한다.
BooleanArgumentMarshaler.set() 메서드는 사실 인수가 필요가 없다.
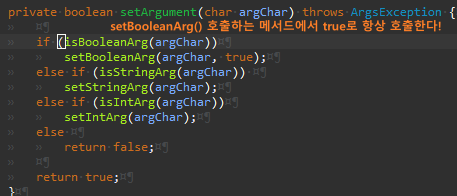
기본으로 false 고, set()을 호출할 경우는 true로 바꿀때 밖에 없기 때문이다.
다른 파생 클래스는 인자가 필요하다.


불필요한 형변환이 늘어나지만, 이렇게 해도 된다.
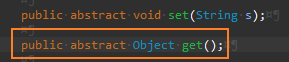
이제 get()메서드를 구현해야 한다. get() 메서드는 구현하기 훨씬 까다롭다.
반환 타입이 여러 개라 Object로 받환해야 한다.
문제는 호출하는 쪽 코드에서 적절한 형변환 코드가 필요하다. 이게 까다롭다.
ArgumentMarshaler
Args

ArgumentMarshaler
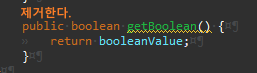
이제 마지막으로 boolean 필드를 파생 클래스로 내린다.
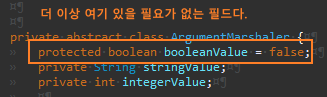

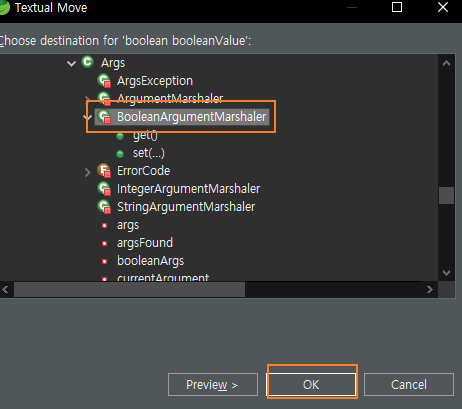
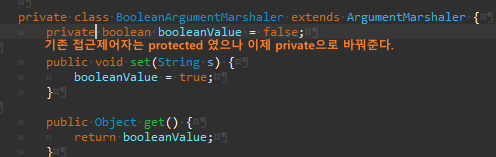
String
과정은 동일하다.
Args
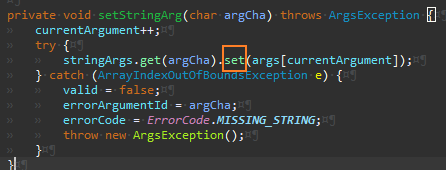

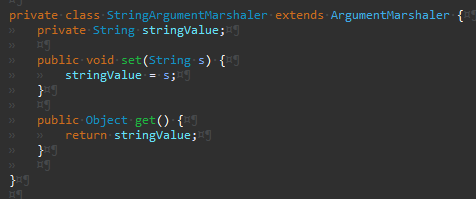
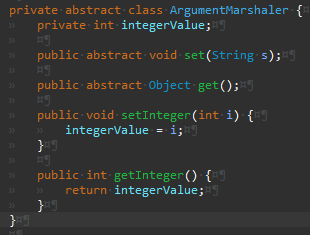
Integer
Args
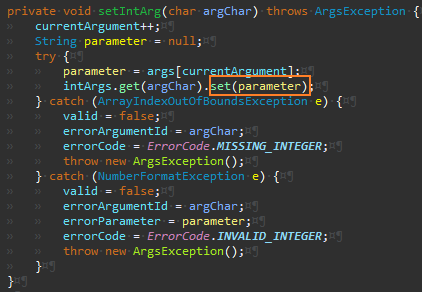
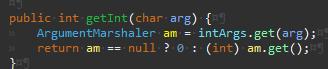
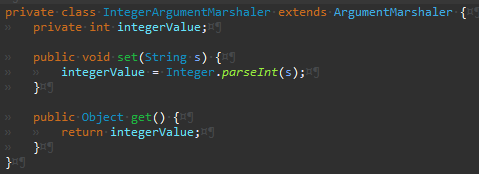
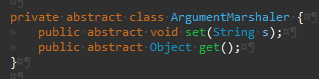
IntegerArgumentMarshaler의 경우 파싱과정에서 예외가 발생할 수 있어 구현이 좀 더 복잡했다.

사용자 정의 예외로 바꾼다.
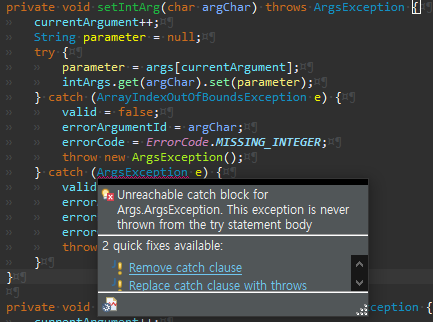
일단 이 오류는 무시한다. 현재 try 구문에서 사용하는 메서드에서 절대로 ArgsException을 던지지 않기 때문에 IDE가 경고를 내보내는 것이다.

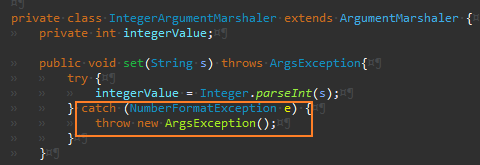
별도 Map에 점진적 이관
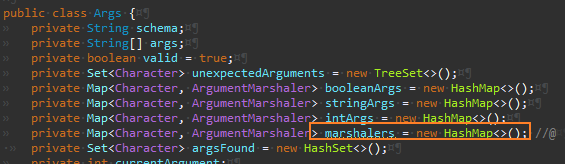
Args
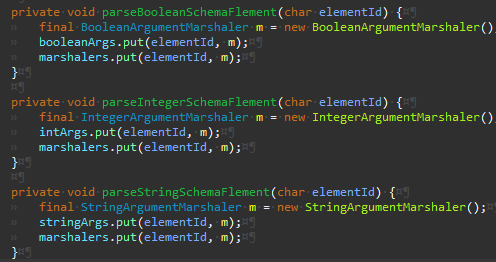
새로 추가한 맵에 동일하게 저장한 것 뿐이다. 기존 코드 동작에 영향은 없다는 점에 주목한다.
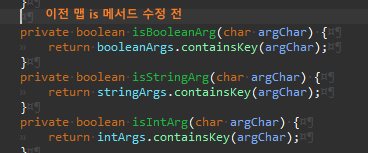

marshalers.get(argChar) 코드 중복이 보인다.
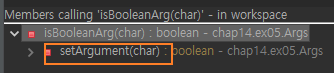
호출하는 곳을 추적해 중복을 제거한다.
Args
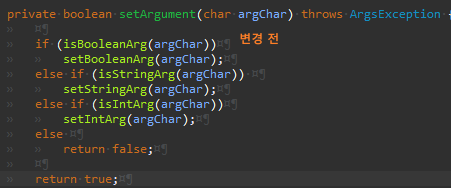
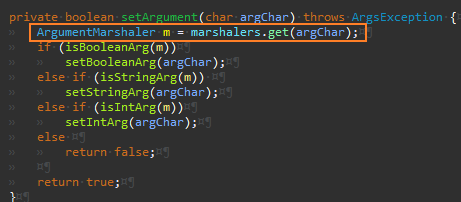

중복을 제거했다. 이후 코드를 보면 더 이상 "isXXXArg" 메서드를 굳이 호출할 필요가 없어 메서드를 인라인했다.
인라인 또한 IDE 도움을 받는다.
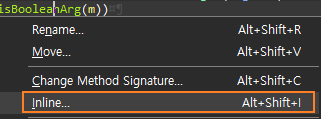
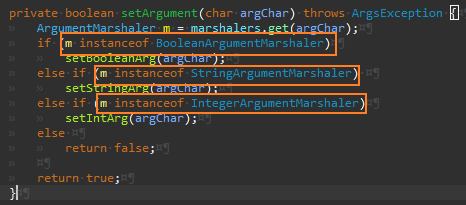
이제 개별 map 사용에서 공통 map을 사용하도록 리팩터링한다. Boolean 부터 시작
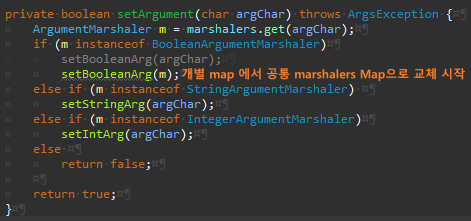
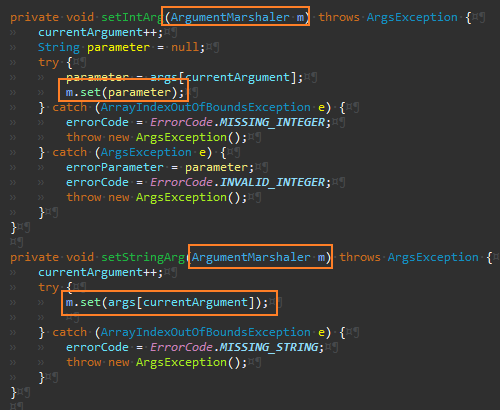
나머지도 동일하게 변경한다.
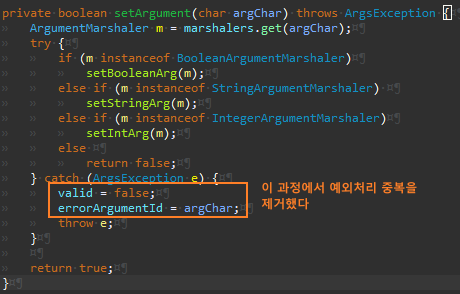
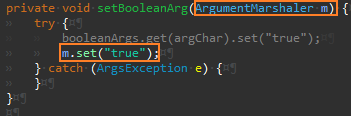
Args.getBoolean() 리팩터링
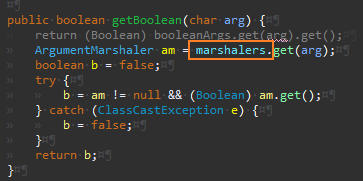
이제 booleanArgs Map 이 사용되는 곳은 없다.
booleanArgs 코드를 제거한다.



나머지 인수유형도 리팩토링
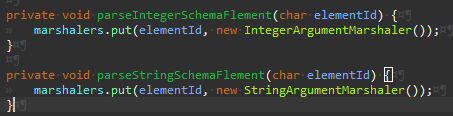
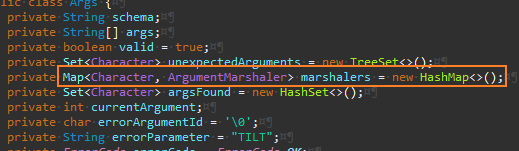
marshalers 맵만 남았다.
parseXXXXSchemaFlement() 메서드도 굳이 선언할 필요 없어 인라인한다.
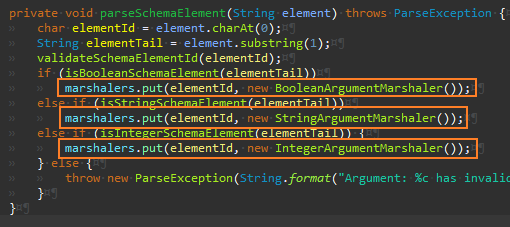
첫 번째 리팩터링 완료
| import java.text.ParseException; import java.util.*; public class Args { private String schema; private String[] args; private boolean valid = true; private Set<Character> unexpectedArguments = new TreeSet<>(); private Map<Character, ArgumentMarshaler> marshalers = new HashMap<>(); private Set<Character> argsFound = new HashSet<>(); private int currentArgument; private char errorArgumentId = '\0'; private String errorParameter = "TILT"; private ErrorCode errorCode = ErrorCode.OK; private enum ErrorCode { OK, MISSING_STRING, MISSING_INTEGER, INVALID_INTEGER, UNEXPECTED_ARGUMENT } public Args(String schema, String[] args) throws ParseException { this.schema = schema; this.args = args; valid = parse(); } private boolean parse() throws ParseException { if (schema.length() == 0 && args.length == 0) return true; parseSchema(); try { parseArguments(); } catch (ArgsException e) { } return valid; } private boolean parseSchema() throws ParseException { for (String element : schema.split(",")) { if (element.length() > 0) { String trimmedElement = element.trim(); parseSchemaElement(trimmedElement); } } return true; } private void parseSchemaElement(String element) throws ParseException { char elementId = element.charAt(0); String elementTail = element.substring(1); validateSchemaElementId(elementId); if (isBooleanSchemaElement(elementTail)) marshalers.put(elementId, new BooleanArgumentMarshaler()); else if (isStringSchemaElement(elementTail)) marshalers.put(elementId, new StringArgumentMarshaler()); else if (isIntegerSchemaElement(elementTail)) { marshalers.put(elementId, new IntegerArgumentMarshaler()); } else { throw new ParseException(String.format("Argument: %c has invalid format: %s.", elementId, elementTail), 0); } } private void validateSchemaElementId(char elementId) throws ParseException { if (!Character.isLetter(elementId)) { throw new ParseException("Bad character:" + elementId + "in Args format: " + schema, 0); } } private boolean isStringSchemaElement(String elementTail) { return elementTail.equals("*"); } private boolean isBooleanSchemaElement(String elementTail) { return elementTail.length() == 0; } private boolean isIntegerSchemaElement(String elementTail) { return elementTail.equals("#"); } private boolean parseArguments() throws ArgsException { for (currentArgument = 0; currentArgument < args.length; currentArgument++) { String arg = args[currentArgument]; parseArgument(arg); } return true; } private void parseArgument(String arg) throws ArgsException { if (arg.startsWith("-")) parseElements(arg); } private void parseElements(String arg) throws ArgsException { for (int i = 1; i < arg.length(); i++) parseElement(arg.charAt(i)); } private void parseElement(char argChar) throws ArgsException { if (setArgument(argChar)) argsFound.add(argChar); else { unexpectedArguments.add(argChar); errorCode = ErrorCode.UNEXPECTED_ARGUMENT; valid = false; } } private boolean setArgument(char argChar) throws ArgsException { ArgumentMarshaler m = marshalers.get(argChar); try { if (m instanceof BooleanArgumentMarshaler) setBooleanArg(m); else if (m instanceof StringArgumentMarshaler) setStringArg(m); else if (m instanceof IntegerArgumentMarshaler) setIntArg(m); else return false; } catch (ArgsException e) { valid = false; errorArgumentId = argChar; throw e; } return true; } private void setIntArg(ArgumentMarshaler m) throws ArgsException { currentArgument++; String parameter = null; try { parameter = args[currentArgument]; m.set(parameter); } catch (ArrayIndexOutOfBoundsException e) { errorCode = ErrorCode.MISSING_INTEGER; throw new ArgsException(); } catch (ArgsException e) { errorParameter = parameter; errorCode = ErrorCode.INVALID_INTEGER; throw new ArgsException(); } } private void setStringArg(ArgumentMarshaler m) throws ArgsException { currentArgument++; try { m.set(args[currentArgument]); } catch (ArrayIndexOutOfBoundsException e) { errorCode = ErrorCode.MISSING_STRING; throw new ArgsException(); } } private void setBooleanArg(ArgumentMarshaler m) { try { m.set("true"); } catch (ArgsException e) { } } public int cardinality() { return argsFound.size(); } public String usage() { if (schema.length() > 0) return "-[" + schema + "]"; else return ""; } public String errorMessage() throws Exception { switch (errorCode) { case OK: throw new Exception("TILT: Should not get here."); case UNEXPECTED_ARGUMENT: return unexpectedArgumentMessage(); case MISSING_STRING: return String.format("Could not find string parameter for -%c.", errorArgumentId); case INVALID_INTEGER: return String.format("Argument -%c expects an integer but was '%s'.", errorArgumentId, errorParameter); case MISSING_INTEGER: return String.format("Could not find integer parameter for -%c.", errorArgumentId); } return ""; } private String unexpectedArgumentMessage() { StringBuffer message = new StringBuffer("Argument(s) -"); for (char c : unexpectedArguments) { message.append(c); } message.append(" unexpected."); return message.toString(); } public String getString(char arg) { ArgumentMarshaler am = marshalers.get(arg); try { return am == null ? "" : (String) am.get(); } catch (ClassCastException e) { return ""; } } public int getInt(char arg) { ArgumentMarshaler am = marshalers.get(arg); try { return am == null ? 0 : (Integer) am.get(); } catch (Exception e) { return 0; } } public boolean getBoolean(char arg) { ArgumentMarshaler am = marshalers.get(arg); boolean b = false; try { b = am != null && (Boolean) am.get(); } catch (ClassCastException e) { b = false; } return b; } public boolean has(char arg) { return argsFound.contains(arg); } public boolean isValid() { return valid; } @SuppressWarnings("serial") private class ArgsException extends Exception { } private abstract class ArgumentMarshaler { public abstract void set(String s) throws ArgsException; public abstract Object get(); } private class BooleanArgumentMarshaler extends ArgumentMarshaler { private boolean booleanValue = false; public void set(String s) { booleanValue = true; } public Object get() { return booleanValue; } } private class StringArgumentMarshaler extends ArgumentMarshaler { private String stringValue; public void set(String s) { stringValue = s; } public Object get() { return stringValue; } } private class IntegerArgumentMarshaler extends ArgumentMarshaler { private int integerValue; public void set(String s) throws ArgsException{ try { integerValue = Integer.parseInt(s); } catch (NumberFormatException e) { throw new ArgsException(); } } public Object get() { return integerValue; } } } |
구조는 개선됐지만, 여전히 미흡한 점이 많다.
특히 setXXX 메서드는 전부 흉하다. 유형을 일일이 확인하기 때문이다.
리팩터링 원칙에 "조건부 로직을 다형성으로 바꾸기" 원칙을 찾아보면 좋다.
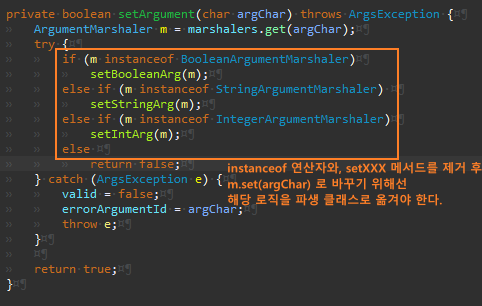
ArgumentMarshaler.set() 을 호출해서 처리하려면 현재 로직을 파생 클래스로 옮겨야 한다.
함수의 인수는 적으면 적을 수록 좋다. 두 개 인수를 넘기지 말고
인수를 하나만 넘기도록 args, currentArgument 인스턴스 변수를 리팩터링한다.
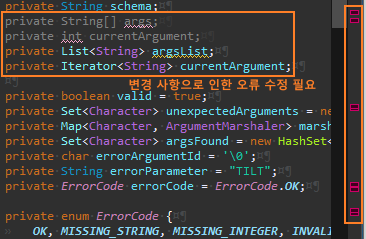
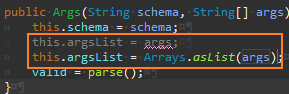
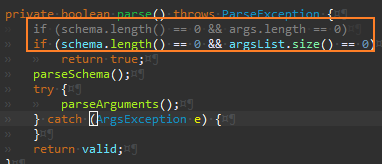
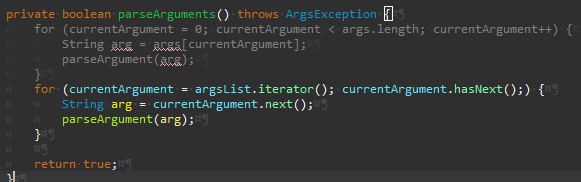
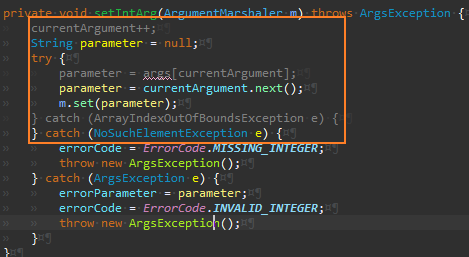
Args.setArgument() 리팩터링
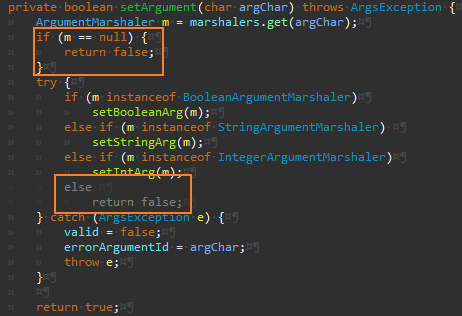
if-else 구분을 제거하기 위해 가장 먼저 예외 케이스(else)를 밖으로 빼냈다.
Boolean 로직이 제일 쉬워 Boolean 부터 처리한다.
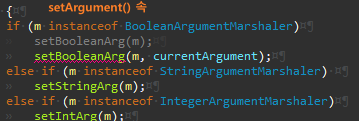
boolean 에선 currentArgument 가 필요없지만, String, Integer에선 필요하다.
이 메서드 리팩터링의 최종 목표인 추상화된 하나의 set() 메서드를 위해선, 선언부를 일치 시켜야 한다.

신규 추상 메서드 추가로 서브 클래스에서 구현하지 않으면 컴파일에 실패할 것이다.
추가 구현하도록 한다.
신규 메서드이므로 아직 세부 구현은 미뤄두고 컴파일만 될 수 있도록 공란으로 둔다.
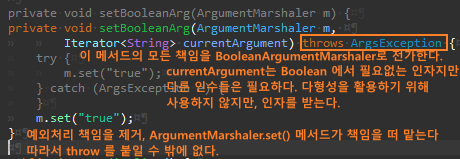
그리고 본래 목적인 Boolean 리팩터링을 진행한다.
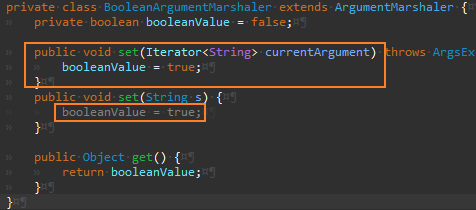
이제 Args.setBooleanArg()을 제거해도 안전하다.
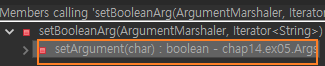
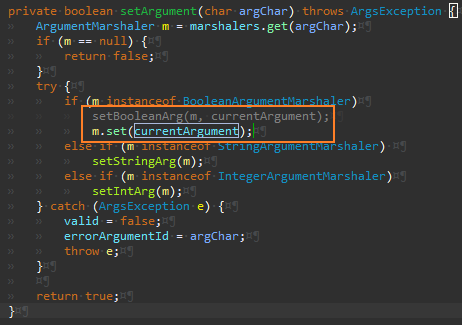
그리고 Args.setBooleanArg 을 호출하는 메서드를 리팩터링한다.

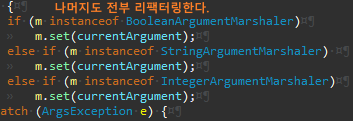
나머지도 동일하게 리팩터링을 진행한다.
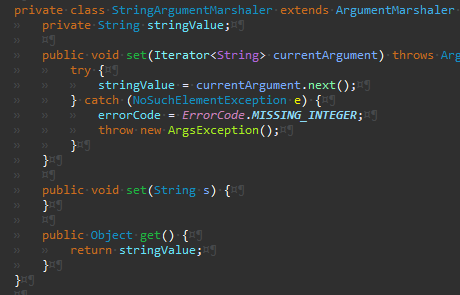
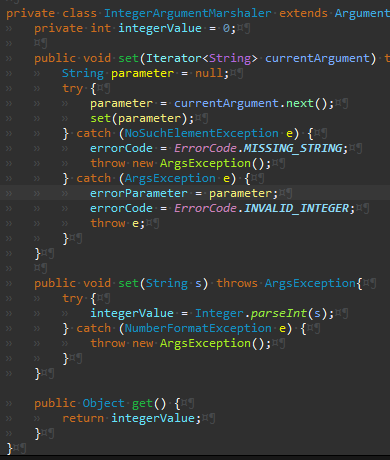
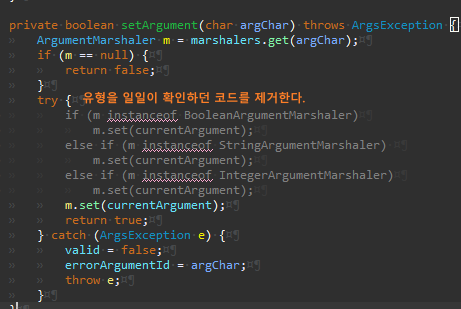
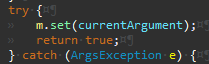

불필요한 메서드 제거를 위해
IntegerArgumentMarshaler 클래스를 좀 더 정리한다.

나머지 ArgumentMarshaler 서브 클래스는 set(String s)에서 아무것도 안했으므로 바로 제거한다.

이제 구조 개선으로 인해 신규 유형 추가가 얼마나 쉬운지 확인한다.
신규 유형 추가 전에 테스트 케이스부터 추가하고 진행한다.
먼저 불필요한 메서드를 인라인한다.
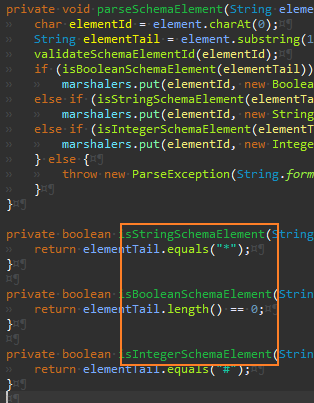
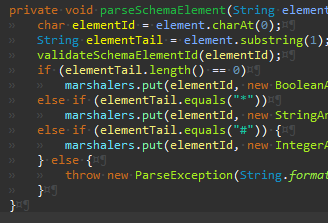
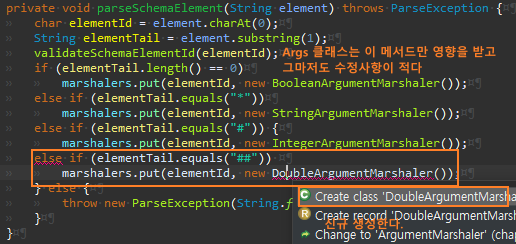
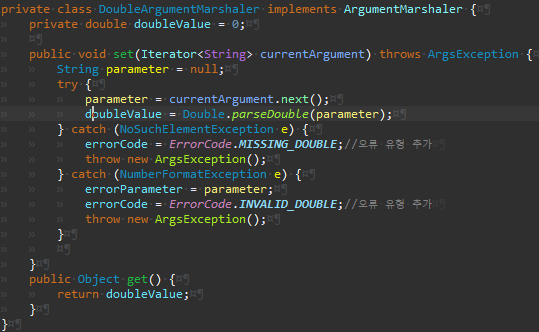
Args.getDouble 메서드를 추가한다.
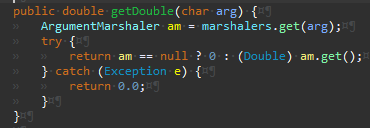
신규 유형 작업이 끝났다.
신규 유형에 대한 예외 메시지 추가
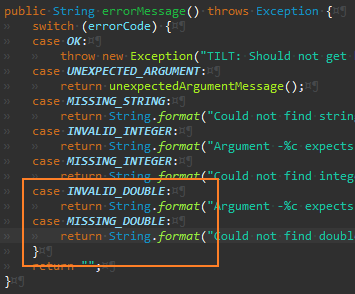
신규 유형에 따른 테스트 케이스도 추가해야 하지만, 따로 예제로 작성하지 않았다.
모든 리팩터링은 사소한 수정 하나에도 계속 단위테스트를 실행에 코드에 깨짐이 없는지 확인해야 한다.
예외 리팩터링
예외 코드 사실 Args와 직접적으로 속하지도 않는다.
ParseException 예외 또한 Args 클래스에 속하지도 않는다.
모든 예외를 ArgsException 클래스로 모은다.
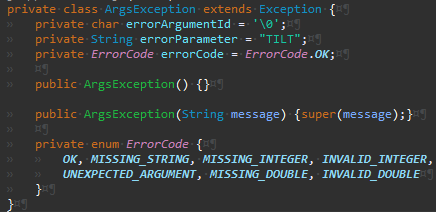
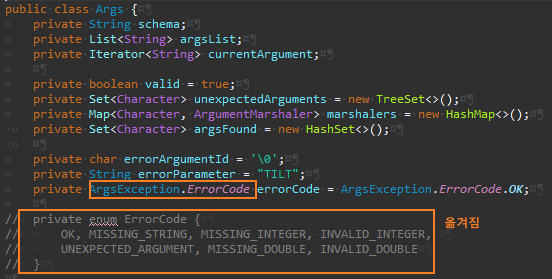
ErrorCode를 옮기면서 오류가 난 것을 위와 같이 수정한다.


오류 코드를 다 수정한 후 모든 ParseException을 커스텀 ArgsException 로 변경한다.




나머지 모든 예외처리 로직을 옮긴다.
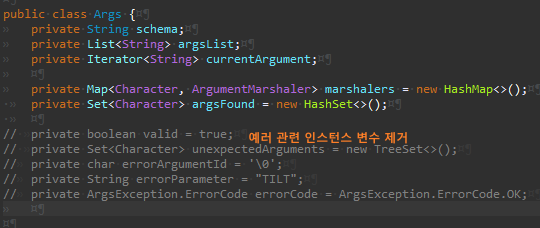
| package chap14.ex05; import java.util.Arrays; import java.util.HashMap; import java.util.HashSet; import java.util.Iterator; import java.util.List; import java.util.Map; import java.util.NoSuchElementException; import java.util.Set; import java.util.TreeSet; public class Args { private String schema; private List<String> argsList; private Iterator<String> currentArgument; private Map<Character, ArgumentMarshaler> marshalers = new HashMap<>(); private Set<Character> argsFound = new HashSet<>(); // private boolean valid = true; // private Set<Character> unexpectedArguments = new TreeSet<>(); // private char errorArgumentId = '\0'; // private String errorParameter = "TILT"; // private ArgsException.ErrorCode errorCode = ArgsException.ErrorCode.OK; public Args(String schema, String[] args) throws ArgsException { this.schema = schema; this.argsList = Arrays.asList(args); // valid = parse(); parse(); } // private boolean parse() throws ArgsException { // if (schema.length() == 0 && argsList.size() == 0) // return true; // parseSchema(); // try { // parseArguments(); // } catch (ArgsException e) { // } // return valid; // } private void parse() throws ArgsException { parseSchema(); parseArguments(); } private boolean parseSchema() throws ArgsException { for (String element : schema.split(",")) { if (element.length() > 0) { String trimmedElement = element.trim(); parseSchemaElement(trimmedElement); } } return true; } private void parseSchemaElement(String element) throws ArgsException { char elementId = element.charAt(0); String elementTail = element.substring(1); validateSchemaElementId(elementId); if (elementTail.length() == 0) marshalers.put(elementId, new BooleanArgumentMarshaler()); else if (elementTail.equals("*")) marshalers.put(elementId, new StringArgumentMarshaler()); else if (elementTail.equals("#")) marshalers.put(elementId, new IntegerArgumentMarshaler()); else if (elementTail.equals("##")) marshalers.put(elementId, new DoubleArgumentMarshaler()); else throw new ArgsException(String.format("Argument: %c has invalid format: %s.", elementId, elementTail)); } private void validateSchemaElementId(char elementId) throws ArgsException { if (!Character.isLetter(elementId)) { throw new ArgsException("Bad character:" + elementId + "in Args format: " + schema); } } private boolean parseArguments() throws ArgsException { for (currentArgument = argsList.iterator(); currentArgument.hasNext();) { String arg = currentArgument.next(); parseArgument(arg); } return true; } private void parseArgument(String arg) throws ArgsException { if (arg.startsWith("-")) parseElements(arg); } private void parseElements(String arg) throws ArgsException { for (int i = 1; i < arg.length(); i++) parseElement(arg.charAt(i)); } private void parseElement(char argChar) throws ArgsException { if (setArgument(argChar)) argsFound.add(argChar); else { // unexpectedArguments.add(argChar); // errorCode = ArgsException.ErrorCode.UNEXPECTED_ARGUMENT; // valid = false; throw new ArgsException(ArgsException.ErrorCode.UNEXPECTED_ARGUMENT, argChar, null); } } private boolean setArgument(char argChar) throws ArgsException { ArgumentMarshaler m = marshalers.get(argChar); if (m == null) { return false; } try { m.set(currentArgument); return true; } catch (ArgsException e) { // valid = false; // errorArgumentId = argChar; e.setErrorArgumentId(argChar); throw e; } } public int cardinality() { return argsFound.size(); } public String usage() { if (schema.length() > 0) return "-[" + schema + "]"; else return ""; } // ArgsException으로 옮김 // public String errorMessage() throws Exception { // switch (errorCode) { // case OK: // throw new Exception("TILT: Should not get here."); // case UNEXPECTED_ARGUMENT: // return unexpectedArgumentMessage(); // case MISSING_STRING: // return String.format("Could not find string parameter for -%c.", errorArgumentId); // case INVALID_INTEGER: // return String.format("Argument -%c expects an integer but was '%s'.", errorArgumentId, errorParameter); // case MISSING_INTEGER: // return String.format("Could not find integer parameter for -%c.", errorArgumentId); // case INVALID_DOUBLE: // return String.format("Argument -%c expects an double but was '%s'.", errorArgumentId, errorParameter); // case MISSING_DOUBLE: // return String.format("Could not find double parameter for -%c.", errorArgumentId); // } // return ""; // } // 제거 errorMessage()을 옮기면서, 메서드 인라인 진행 // private String unexpectedArgumentMessage() { // StringBuffer message = new StringBuffer("Argument(s) -"); // for (char c : unexpectedArguments) { // message.append(c); // } // message.append(" unexpected."); // // return message.toString(); // } public String getString(char arg) { ArgumentMarshaler am = marshalers.get(arg); try { return am == null ? "" : (String) am.get(); } catch (ClassCastException e) { return ""; } } public int getInt(char arg) { ArgumentMarshaler am = marshalers.get(arg); try { return am == null ? 0 : (Integer) am.get(); } catch (Exception e) { return 0; } } public double getDouble(char arg) { ArgumentMarshaler am = marshalers.get(arg); try { return am == null ? 0 : (Double) am.get(); } catch (Exception e) { return 0.0; } } public boolean getBoolean(char arg) { ArgumentMarshaler am = marshalers.get(arg); boolean b = false; try { b = am != null && (Boolean) am.get(); } catch (ClassCastException e) { b = false; } return b; } public boolean has(char arg) { return argsFound.contains(arg); } // 제거 // public boolean isValid() { // return valid; // } @SuppressWarnings("all") private class ArgsException extends Exception { private char errorArgumentId = '\0'; private String errorParameter = "TILT"; private ErrorCode errorCode = ErrorCode.OK; public ArgsException() { } public ArgsException(String message) { super(message); } public ArgsException(ErrorCode errorCode) { this.errorCode = errorCode; } public ArgsException(ErrorCode errorCode, String errorParameter) { this.errorCode = errorCode; this.errorParameter = errorParameter; } public ArgsException(ErrorCode errorCode, char errorArgumentId, String errorParameter) { this.errorCode = errorCode; this.errorArgumentId = errorArgumentId; this.errorParameter = errorParameter; } public char getErrorArgumentId() { return errorArgumentId; } public void setErrorArgumentId(char errorArgumentId) { this.errorArgumentId = errorArgumentId; } public String getErrorParameter() { return errorParameter; } public void setErrorParameter(String errorParameter) { this.errorParameter = errorParameter; } public ErrorCode getErrorCode() { return errorCode; } public void setErrorCode(ErrorCode errorCode) { this.errorCode = errorCode; } public String errorMessage() throws Exception { switch (errorCode) { case OK: throw new Exception("TILT: Should not get here."); case UNEXPECTED_ARGUMENT: return String.format("Argument -%c unecpected.", errorArgumentId); case MISSING_STRING: return String.format("Could not find string parameter for -%c.", errorArgumentId); case INVALID_INTEGER: return String.format("Argument -%c expects an integer but was '%s'.", errorArgumentId, errorParameter); case MISSING_INTEGER: return String.format("Could not find integer parameter for -%c.", errorArgumentId); case INVALID_DOUBLE: return String.format("Argument -%c expects an double but was '%s'.", errorArgumentId, errorParameter); case MISSING_DOUBLE: return String.format("Could not find double parameter for -%c.", errorArgumentId); } return ""; } private enum ErrorCode { OK, MISSING_STRING, MISSING_INTEGER, INVALID_INTEGER, UNEXPECTED_ARGUMENT, MISSING_DOUBLE, INVALID_DOUBLE } } private interface ArgumentMarshaler { public abstract void set(Iterator<String> currentArgument) throws ArgsException; public abstract Object get(); } private class BooleanArgumentMarshaler implements ArgumentMarshaler { private boolean booleanValue = false; public void set(Iterator<String> currentArgument) throws ArgsException { booleanValue = true; } public Object get() { return booleanValue; } } private class StringArgumentMarshaler implements ArgumentMarshaler { private String stringValue; public void set(Iterator<String> currentArgument) throws ArgsException { try { stringValue = currentArgument.next(); } catch (NoSuchElementException e) { // errorCode = ArgsException.ErrorCode.MISSING_INTEGER; throw new ArgsException(ArgsException.ErrorCode.MISSING_INTEGER); } } public Object get() { return stringValue; } } private class IntegerArgumentMarshaler implements ArgumentMarshaler { private int integerValue = 0; public void set(Iterator<String> currentArgument) throws ArgsException { String parameter = null; try { parameter = currentArgument.next(); integerValue = Integer.parseInt(parameter); } catch (NoSuchElementException e) { // errorCode = ArgsException.ErrorCode.MISSING_STRING; throw new ArgsException(ArgsException.ErrorCode.MISSING_STRING); } catch (NumberFormatException e) { // errorParameter = parameter; // errorCode = ArgsException.ErrorCode.INVALID_INTEGER; throw new ArgsException(ArgsException.ErrorCode.INVALID_INTEGER, parameter); } } public Object get() { return integerValue; } } private class DoubleArgumentMarshaler implements ArgumentMarshaler { private double doubleValue = 0; public void set(Iterator<String> currentArgument) throws ArgsException { String parameter = null; try { parameter = currentArgument.next(); doubleValue = Double.parseDouble(parameter); } catch (NoSuchElementException e) { // errorCode = ArgsException.ErrorCode.MISSING_DOUBLE; throw new ArgsException(ArgsException.ErrorCode.MISSING_DOUBLE); } catch (NumberFormatException e) { // errorParameter = parameter; // errorCode = ArgsException.ErrorCode.INVALID_DOUBLE; throw new ArgsException(ArgsException.ErrorCode.INVALID_DOUBLE, parameter); } } public Object get() { return doubleValue; } } } |
이제 Args 가 던지는 예외는 ArgsException 뿐이다.
Args는 예외/오류 처리 코드와 목적 코드가 완전히 분리됐다.
개별 클래스로 분리
이제 하나의 클래스 파일에 있던 내부 클래스를 각자 클래스로 분리한다.
IDE 도움을 받는다.
이클립스 기준 Alt + Shift + T
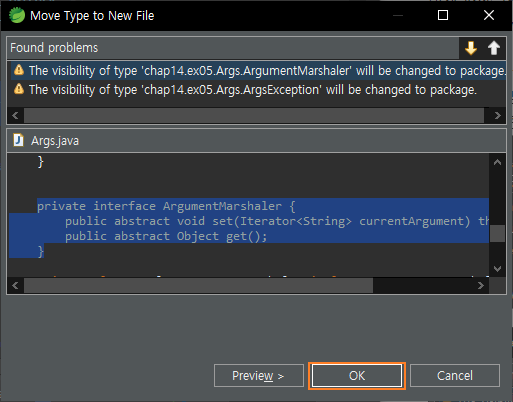
최종
소프트웨어 설계는 분할만 잘해도 품질이 크게 올라간다.
관심사를 분리하면 코드를 이해하고 보수하기 쉬워진다.
특히나 ArgsException.errorMessage() 메서드는 Args 에 있었을 때 명백히 SRP를 위반한 사례다.
Args 클래스 책임은 인수를 처리하는 것인데, errorMessage()는 추가로 오류 메시지 형식을 결정하는 책임을 가졌기 때문이다.
결론
돌아만 가는 코드만으로는 부족하다.
설계와 구조를 개선할 시간이 없다고 변명은 말이 안된다. 나쁜 코드로 인한 악영향기 더 크기 때문이다.
묵은 나쁜 코드일 수록 좋은 코드로 바꾸기 더욱 힘들어진다. 처음부터 깨끗한 코드를 유지하는 것이 훨씬 쉽다.